May 2024 Release Notes
Process Explorer (2024-05-29)
Multi-sliders
The slider controls in Process Explorer use two multi-sliders to explore the events of individual objects and connections within your process. In these multi-sliders, each object or connection appears as a different slider and is color coded to match the objects in the process graph. For more information on using multi-sliders, see Multi-object Process Explorer.
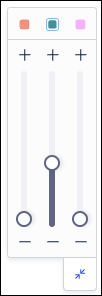
Moving a slider up will add the next most common event or connection for that specific object, while sliding down removes the least frequent event or connection that is currently displayed for that object. For example, you can adjust the slider for one object upwards to add the next most frequent event for that object to the graph while the remaining objects are not changed. However, if the event being added does not connect to the events currently displayed for this object, additional events will be added to connect the event being added.
If the event being added is shared with other objects, it is only added for the object corresponding to the slider you adjusted. However, for the other objects, this event will display empty circles to indicate that it is not included.
 |
If a slider has been used to explore the current process, the colored square corresponding to that object will be highlighted with a blue border, even if the multi-slider is collapsed (see the middle object in the screenshot below). This indicates that events or connections have been added to the process flow currently shown.

JDBC Extractor version 2.97.1 (2024-05-29)
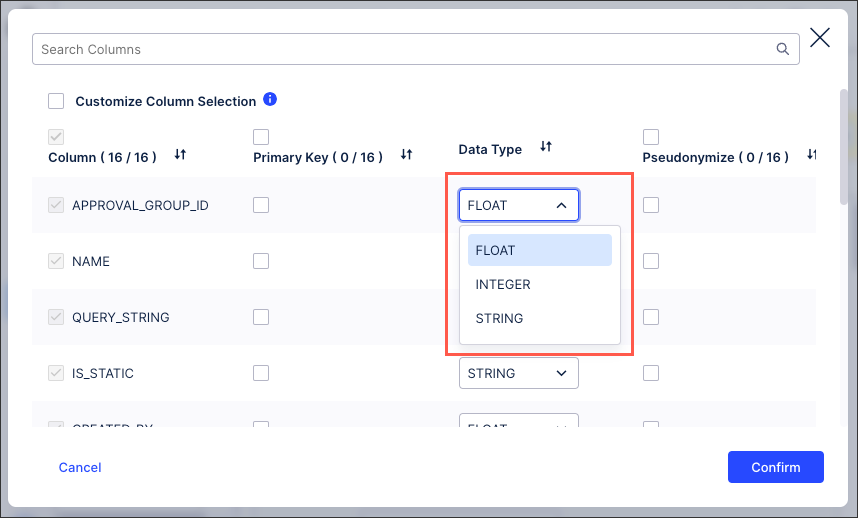
Type casting between integer and float data types with Oracle databases
With this version of the extractor, you can now configure type casting between Integer and Float data types when setting up your Oracle extraction tasks.
For an overview of supported databases and their features (including Oracle), see: Databases.
 |
Material Allocation app (object-centric) version 1.1.0 (2024-05-28)
Compatibility changes to KPIs
In this version of the object-centric Material Allocation app, we’ve made some changes to KPI names in the Knowledge Model to maintain compatibility with the Knowledge Models for other Inventory Management apps. If you made customizations to the KPIs in an earlier version of the app, you’ll need to reapply these to the renamed KPIs. For the instructions to update the Material Allocation app, see Updating the object-centric Material Allocation app.
Object-centric process mining (2024-05-28)
Improvements in the perspective builder
We're upgrading the perspective builder to make it easier for analysts to build custom perspectives for processes. You'll see these changes in your user interface soon, on the Perspectives page in the Objects and Events UI.
You can now click an object type in the perspective or the object list to select it. You’ll get an object details panel where you can view and edit the other object types that are related to it in the perspective. There’s also an Exclude button to exclude the object type. (Previously, when you clicked an object, you’d get the option to exclude it from the perspective.)
When you select an object, we’ll put the focus on it by highlighting it and centering the graph on it, and collapsing multiple relationship lines between pairs of objects into a single line. By default, we'll also only show the objects adjacent to your selected object. You can change that setting in the display options.
We've simplified the flow and reduced the number of clicks to add an object or choose a strategy for a relationship.
You can now include and embed the same relationship, and we've made it clearer which is which.
We’ve put in some new display options that make it easier to show only the things that are relevant to you.
SAP Ariba Extractor (2024-05-27)
Extract data from columns with localized values
If you’re using SAP Ariba’s Master Data Retrieval API to extract data from master data tables, our extractor now gets data from columns with localized values (for example, Name_en, Description_en), which it couldn’t do before. We’ve added these columns to the column configuration in your existing extractions, so you don’t need to change them. You do need to update the metadata, either by running a full load of the data model, or by running a delta load with the option “Include metadata changes”. Scheduled delta loads that don’t have that option selected will fail until you’ve done that.
The tables where you’ll get the additional columns are: Accounts, Account_types, Bankaccountidtype, Bankaccounttype, Bankidtype, Chargetype, Commoditycodes, Commonsuppliers, Costcenters, Countries, Currency, Generalledgers, Glindicator, Groups, Incoterms, Itemcategory, Languages, Localeids, Partitionedcommoditycodes, Paymentmethodtype, Paymentterms, Procurementunits, Taxcodes, Uoms, Users. For the extractor documentation, see SAP Ariba.
ServiceNow Extractor (2024-05-27)
Configuration Option for the "Order-by" parameter
The User Order-by Parameter in Request configuration option enables the use of the ordering parameter in all API requests for an extraction. Enabling this option ensures data integrity by preventing missing records and duplicates. However, it will also lead to a longer extraction time and an increased load on the source system. To help minimize this impact, we recommend that you apply partitioning to reduce both the peak impact and the duration of the system being occupied or increase the batch size, which increases the peak impact but decreases the duration of the system being occupied.
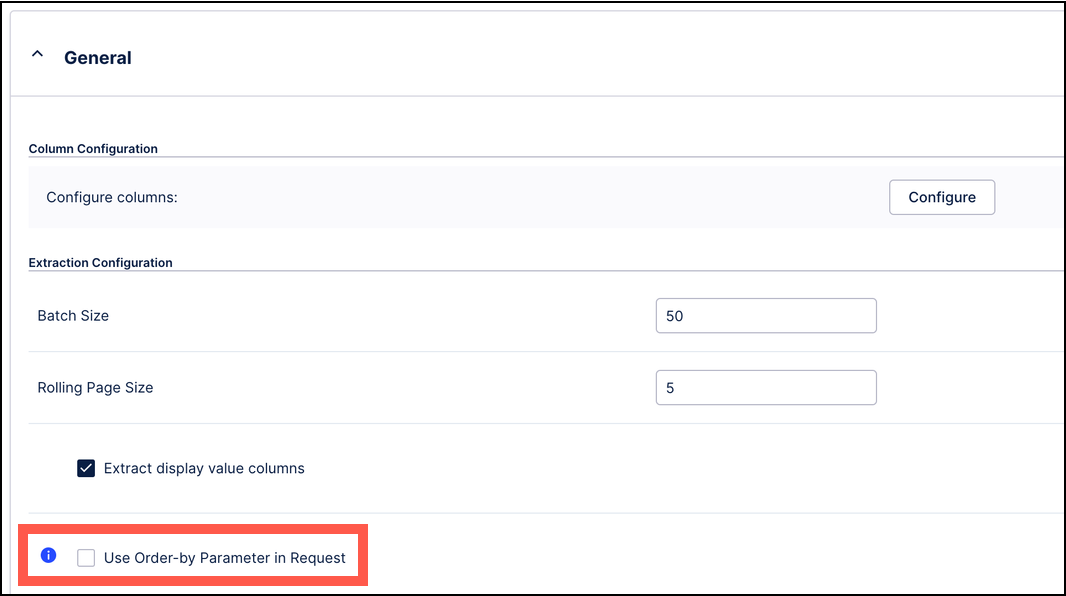 |
This option is disabled by default but can be enabled at the table level based on specific needs. This option can also be enabled via the extraction settings, which also enables it for all tables in the underlying extraction job.
Celonis Process Management (formerly Symbio) (week of 2024-05-27)
Seamless navigation from the Celonis Platform to Celonis Process Management products
Team admins can quickly and easily enable seamless access to Celonis Process Management products.
Once enabled, users signed in to the Celonis Platform can navigate to Celonis Process Management products from the Celonis Platform Navigation bar.
Users with analyst and admin permissions can access Process Designer. If also enabled, all users can access Process Navigator.
For more more information, see Enabling access to Celonis Process Management.
Note
Users must have a Process Designer or Process Navigator account to access Celonis Process Management products.
Studio (2024-05-27)
Removal of package 'Created By' avatar
Based on valuable customer feedback, we have decided to temporarily withhold the avatar feature indicating the ‘creator’ of package in Studio and Apps. This decision enables us to effectively address our customers’ needs. The feature will be re-evaluated and reintroduced in a manner that better meets the expectations of our users.
Procurement Starter Kit (object-centric) version 1.1.0 (2024-05-24)
Deep dive into planning parameters and contract leakage
In this version of the object-centric Procurement Starter Kit, we've extended the use cases in the Process Cockpit:
The new Planning Parameters Deep Dive lets you identify discrepancies between procurement lead times and actual lead times, so you can see when you need to update your planning parameters. This view is also available in the Validation Cockpit.
The Contract Usage Deep Dive now includes the Contract Leakage value opportunity, like the case-centric version of the Starter Kit does.
For the Procurement Starter Kit documentation, see Procurement Starter Kit - object-centric.
Object-centric process mining (2024-05-23)
Make sure your IDs are unique in each event type
If the IDs that you use in the ID field for objects and events aren't unique, you might end up with inaccurate results for metrics and KPIs, such as an incorrect count of events for an event type. For example, if you're using data from more than one source system to create objects and events, you might get duplicated identifiers across the source systems.
We're about to start checking that your event IDs are unique in each event type. We'll make these checks whenever you load a perspective with your built objects and events (using the Load Data Model button in the data pool). At first we'll just return a warning message to let you know which transformations need to be fixed. About four weeks after that, the perspective load will fail if there are any duplicate event IDs in an event type.
If you see this warning message, here's how to fix the issue:
If you're using data from more than one source system to create events, concatenate the name of the source system as part of your event ID. In the Celonis catalog transformations, you can fill in the local parameter
sourceSystemto name the source system instance. Keep it short, though, as long IDs have a performance impact. Object and Event IDs has guidance on this.If that's not the issue, check your source system data for duplicate records. Perspectives includes a method to do this. If you can't fix the problem in the source system, you can use filtering during data extraction to remove unwanted duplicate records, or remove the duplicates in pre-processing. Data extraction and pre-processing has instructions to set up a pre-processing stage.
If that's not the issue either, you might be including the same data set in more than one way - for example, if you include the same source system data in two different sets of pre-transformed data, and use them both in transformations to create events. This isn't good practice as you'll be creating a representation of the same real event more than once in the system. You should change the setup of your transformations so it doesn't happen - for example, by adding a filter condition. Object and Event IDs has more details.
Object-centric process mining (2024-05-22)
Disable and re-enable Celonis catalog transformations
You can now disable individual transformations installed from the Celonis catalog, and re-enable them again at any time. Use this function if you’ve installed a Celonis catalog process, but there are some of the Celonis object types and event types that you don’t need, or don’t have data for, or are building with data from a set of transformations for another source system. You can re-enable the transformation at any time if you do need it in the future. Previously, you would have needed to create a full overwrite for the transformation to produce an empty result set, so if you have any of these, you can get rid of them and disable those transformations instead.
The toggles to disable and enable the Celonis catalog transformations are available in the listing on the Transformations page of the Objects and Events user interface. You’ll also get them if you view the transformations for an object type or event type in the Objects or Events pages. By default, your installed Celonis catalog transformations are all enabled. For the instructions to install the Celonis catalog transformations, see Quickstart: Extract and transform your data into objects and events
Action Flows (2024-05-16)
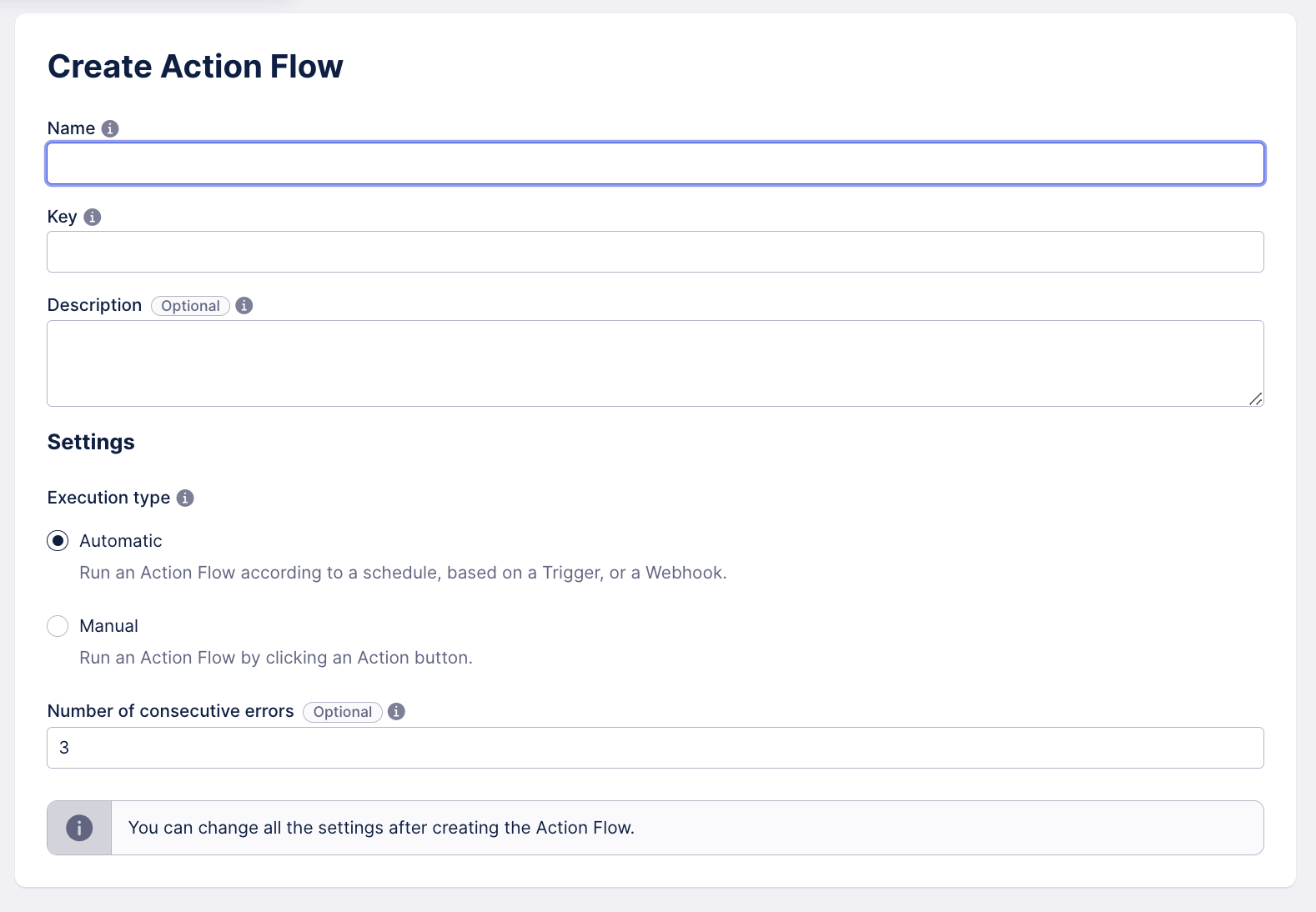
Changes in the Action Flow creation process
We've added some new settings to the Action Flow creation flow. Now, when creating an Action Flow, in addition to providing the name and the description for your Action Flow, you also have to select the Automation type, and (optionally) define the number of consecutive errors, after which the Action Flow gets deactivated.
There are two automation types to select from: automatic and manual. If the automation type is set to manual, the Action Flow has to be started manually and its scheduling will be set to On-demand. This scheduling type is necessary to start the Action Flow using an Action button or a Task.
If the automation type is set to automatic, the Action Flow will be executed according to a set schedule. and it will be set to According to scheduling. Please note that adding a Trigger or a Webhook as the first module will automatically change the scheduling to Immediately.
Apart from selecting the automation type, you can also define the number of consecutive errors after which the Action Flow is deactivated.
Both settings can be changed after the Action Flow has been created.
 |
Process Explorer (2024-05-15)
Multi-object event counts
The Process Explorer interface now shows the event counts broken out by object type, allowing for a more accurate count for shared events. This new feature shows the total count of the current metric for each object type next to the colored square corresponding to that object type in the process flow. Previously, the event count shown was across all objects and users were required to view the event details to see the individual event count for each object type.
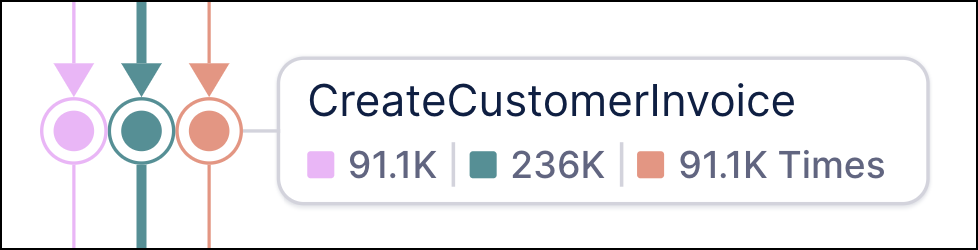 |
This update also fixes the issue with event counts displaying as “No Data” that was caused by adjusting event names via PQL statements in one or more object types.
JDBC Extractor version 2.96.1 (2024-05-14)
Extract from Google BigQuery external tables
With this version of the extractor, if you’re extracting data from a Google BigQuery database, you can now get data from external tables, which reference data stored outside BigQuery, as well as from standard BigQuery tables.
For the instructions to upgrade the JDBC Extractor, see Updating JDBC extractors.
Studio (2024-05-13)
Upgraded Apps and Studio navigation with enhanced View editing experience
We've been busy enhancing the Studio, your workbench for analyzing data, exploring processes, and building solutions. These streamlined interfaces make building views and solutions faster, more intuitive, and a much more joyful end-to-end experience for you.
To help you unlock the potential of our new Studio features:
Take our Celonis Academy training track: Building Views in Studio.
Join our Studio team for a webinar series: Enhanced Studio Experience Series.
View our updated user guides and documentation: Studio.
Enhanced Studio and Apps features include:
As of today, everyone has access to our Studio and Apps enhancements, including the following exciting updates:
Navigation: A much more intuitive and coherent Apps (for business users) and Studio navigation experience with improved search and pinning.
Watch our new Introduction to Apps video here:
Content management: Improved experience for managing your work in Studio, including guided creation flows and Trash to clean up unwanted content.
View editing: A smarter View editing experience complete with:
Drag and drop layout building for fullscreen or custom height dashboards with tabs.
Guided component config and easy-to-use chart templates.
Simplified interface to create reusable coloring rules directly from your components.
Integrated and configurable filterbar, allowing you to provide various filter options for your users.
And in-built table actions for sending emails, exporting content, and running action flows.
Enhanced PQL building functionality: Simplify the selection and aggregation of data while building components. Write PQL queries locally and see results immediately or tap into a Knowledge Model.
Knowledge Model improvements: Create and reference both calculated attributes and augmented attributes in your content.
Reusable variables: Use Knowledge Model and View variables to efficiently customize your content to meet your use case.
Watch our new video about our navigation and view editing enhancements video here:
Admin & Settings (2024-05-13)
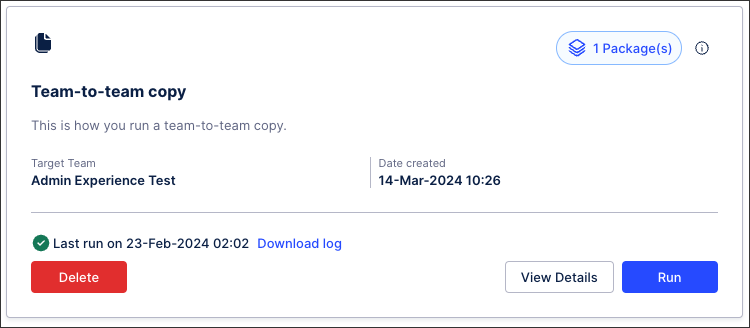
Team-to-team copy of data pools and Studio packages in general availability for Premium Sandbox subscribers only.
Our team-to-team copy feature is now in general availability for Premium Sandbox Subscribers. Team admins can now bulk copy data pools and Studio packages between Celonis Platform teams. By creating and saving a copy run, you no longer need to manually recreate and reconfigure your data integration and Studio content in additional teams.
When copying content between teams, the following conditions apply:
Data pools: The latest released version of your data pool is copied where available. If your data pool exists in draft mode only, the draft will be copied. This excludes any data integration schedules you have configured in your data pool, however any time based schedules from the target team are reapplied to the new team. This means that the times for productive schedules aren't impacted.
Packages: Packages with Action Flows can be copied but the Action Flows are not updated in your target team.
For more information about the Team-to-team copy feature, see: Team-to-team copy.
 |
Oracle Fusion BICC Extractor (2024-05-13)
Full support for timestamp columns (Limited Availability)
The Oracle Fusion BICC Extractor now extracts time as well as date information from timestamp columns. New extractions will automatically load the additional data. To update data that's already been extracted, run a full load after 13 May, when the new version of the extractor will be on all clusters. For the extractor instructions, see Oracle Fusion Cloud BICC.
The BICC Extractor is in Limited Availability status. To get access as an early adopter, ask your Celonis point of contact.
Accounts Payable Starter Kit, object-centric (version 1.1.0) and case-centric (version 1.3.0) (2024-05-10)
New Paid On-Time formula, more KPIs and inefficiencies added
For these new versions of the object-centric and case-centric Accounts Payable Starter Kit, we’ve rebuilt the ‘Paid On-Time’ formula and classification. The new method classifies invoices into Early, On-Time, and Late, and distinguishes between cash discount and non-cash discount invoices. The new calculation dynamically adjusts the due date per invoice line depending on the cash discount amount taken, removing the possibility of an invoice being flagged as an early payment due to a cash discount being taken.
For Invoices with no cash discount taken, the latest payment term is used to calculate the invoice due date.
For Cash Discount Invoices, the amount taken is compared against the Cash Discount available in the payment terms.
When the cash discount taken is equal or less than the middle payment term cash discount amount, then the middle payment term is used as the due date for the On-Time Payment calculation.
When the cash discount taken is greater than the middle payment term cash discount, then the earliest payment term is used to calculate the Invoice due date.
We’ve also added new KPIs and inefficiencies to the Days Payable Outstanding use case tab:
Maximum DPO based on Best terms KPI
Maximum DPO based on PO terms KPI
Unfavorable PT mismatch (Inv/PO) Inefficiency
Unfavorable PT mismatch (Inv/MD) Inefficiency
Avg. Days Paid Early (only in the object-centric kit)
Avg. Days Paid Late (only in the object-centric kit)
In the case-centric kit, we’ve added profile views to all inefficiencies, except Duplicate Invoices. The profile views include information about available pre-built applications that can be used to resolve the inefficiencies, as well as possible root causes for them.
For the documentation for the object-centric kit see Open Credit Memo app - object-centric, and for the case-centric kit see Open Credit Memo app - case-centric.
Open Credit Memo app (object-centric) version 1.1.0 (2024-05-10)
Enhanced credit memo details view, and alternative value realization
The object-centric Open Credit Memo app’s Credit Memo Details profile view now includes more actions and a redesigned vendor overview, which lets users choose to view documents by company code or by vendor name. We’ve also redesigned the Validation and Value assessment view for easier and faster configuration, including an alternative value realization method that doesn’t require the augmented credit memo status. For the instructions to upgrade the app, see Updating the object-centric Open Credit Memo app.
Object-centric process mining (2024-05-07)
Schedule transformations for individual perspectives (Limited Availability)
Instead of running the complete OCPM data job to create objects and events for all your enabled processes, you can now set up schedules to run the transformations for one perspective at a time (or more than one if you want). This feature is currently in Limited Availability - if you'd like to try it out now, open a Support ticket to request it. We're planning to have it in General Availability soon.
When you run the OCPM data job through a schedule where you've selected perspectives, we'll identify all the objects and events that are part of those perspectives. Then we’ll run only the transformations that are needed to create those objects and events from your source system data. You can create dedicated schedules for the Celonis-supplied perspectives for the Celonis catalog processes, and also for your custom perspectives. For the full instructions, see Running transformations.
Because Data Integration can only run one instance of a data job at a time, we've added an execution setting to enable queuing of data jobs. When this is enabled, if an instance of the OCPM data job (or any data job) is running and another instance of the same data job is scheduled to start, the second instance will be queued until the first finishes. If queuing of data jobs isn't enabled, the second instance would be skipped, as it would before this feature. While the feature is in Limited Availability, you'll need to enable queuing of data jobs manually for every schedule where you've selected perspectives. When the feature enters General Availability, queuing of data jobs will become the default behavior for all schedules in the OCPM Data Pool.
Queuing of data jobs is available in every data pool, not just the OCPM Data Pool. So you can activate it for other data jobs if you want to - including case-centric data jobs. In every data pool that doesn't have object-centric data models active, queuing of data jobs will be off by default. In every data pool that does (if you're using the feature that gives you object-centric data models in all your data pools), it will be on by default.
Baseline Date Optimizer App (case-centric) version 1.0.0 (2024-05-02)
Identify and resolve unfavorable baseline date mismatches (Limited Availability)
Our new Baseline Date Optimizer app provides you with a step-by-step guide to identify areas with frequent baseline date mismatches that impact free cash flow, or cause loss of cash discount. The app can compare the invoice baseline date against multiple other dates from both the invoice receipt and the goods receipt. When you’ve chosen an optimization strategy using this information, the Action View shows a prioritized list of open invoices based on the value potential, making it easy to use the best baseline date. For the full documentation, see Baseline Date Optimizer app - case-centric.
The Baseline Date Optimizer app is built for the case-centric version of the Accounts Payable business process. You can download the app from the Celonis Marketplace - it’s in Limited Availability status, so click Request Access to request the package. When we’ve approved your request, go back to Marketplace, and the button will say Get it now, so you can download the package.