Creating extraction tasks using the visual editor
Extraction tasks isolate and extract specific data tables from your source system for import into the Celonis Platform. Data engineers configure these extractions to establish the clean, high-fidelity data foundations required to discover process bottlenecks, such as targeting purchase order tables (EKKO and EKPO) to analyze a Procurement workflow.
Create extraction tasks manually using the visual editor within your data jobs, or edit existing tasks inherited from a process connector.
To create extraction tasks programmatically using the API instead of the visual editor, see: Extractions Editor and AI Assistant overview.
For a video overview of extraction tasks:
Ensure your target source system supports visual extractions. Review the feature capabilities for your environment before proceeding:
To create extraction tasks from your data pool diagram using the visual editor:
Click Data Jobs and select your target data connection scope.
In the extraction row, click + Add.

In the task name field, enter a unique identifier that reflects your business domain (for example, enter
SAP_MM_PO_Extractionto isolate procurement data), then click Save.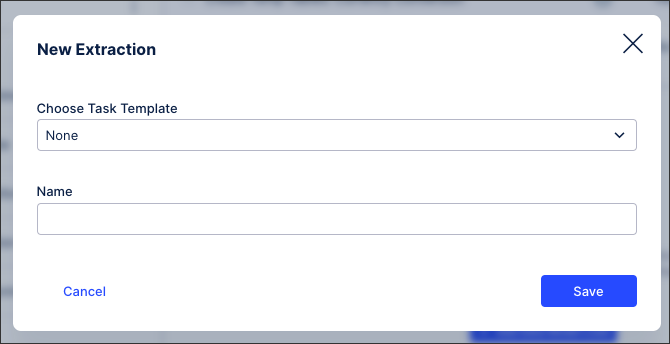
The task is created and displayed.
Configure your extraction parameters and data filters.
Configure your extraction parameters and data filters. For example, change the replication method to Delta and apply a date filter on the document creation field (
AEDAT >= '2025-01-01') to isolate records from the current fiscal year. For a full directory of available settings, see: Extraction task configuration.
You can manage existing extraction tasks by clicking Options.
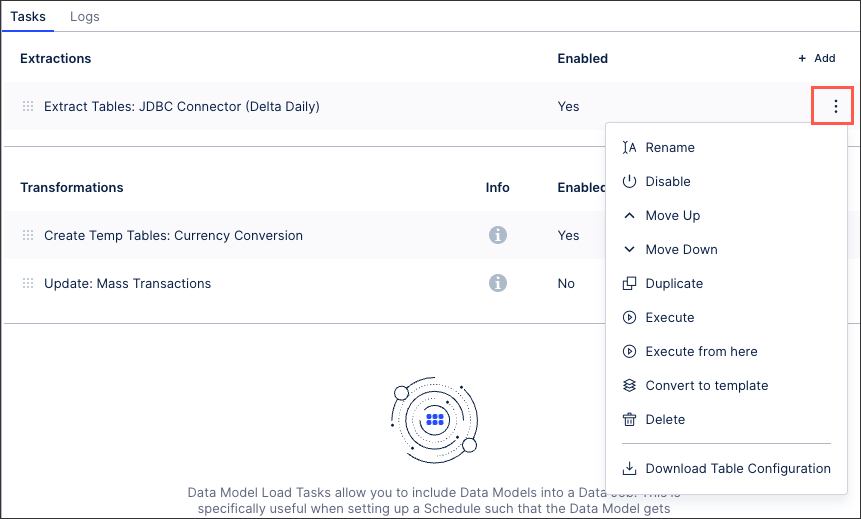 |
You have the following options here:
Rename: Update the name of the extraction task.
Enable / disable: Control whether the extraction task should be enabled or disabled for executions.
Move up / down: Change the order in which this task is performed in a full execution.
Duplicate: Create a copy of the extraction task in the existing data job.
Execute: This allows you to manually execute just this task on demand. For more information about executing data jobs, see: Executing data jobs.
Execute from here: This allows you to manually execute this and all following tasks on demand. For more information about executing data jobs, see: Executing data jobs.
Convert to template /copy to regular task: The task becomes a template and can be added to other data jobs or used to extend the template. If the task is already a template, you can create a regular task from it. For more information about task templates, see: Creating data job task templates.
Delete: This deletes the task and all associated content, with no recovery possible.
Download table configuration: This gives you offline access to a zipped file containing any relevant Excel workbook copies of your table configuration.