Setting up Duplicate Invoice Checker
After verifying that all prerequisites have been ticked off, it’s now time to set up the app:
Download the app from Marketplace.
Note
The components in the "Action View" are initially broken and will only be populated if the results of the ML Sensor are available in the data model.
Assign a data model to the data model variable in the package settings.
Configuring the knowledge model
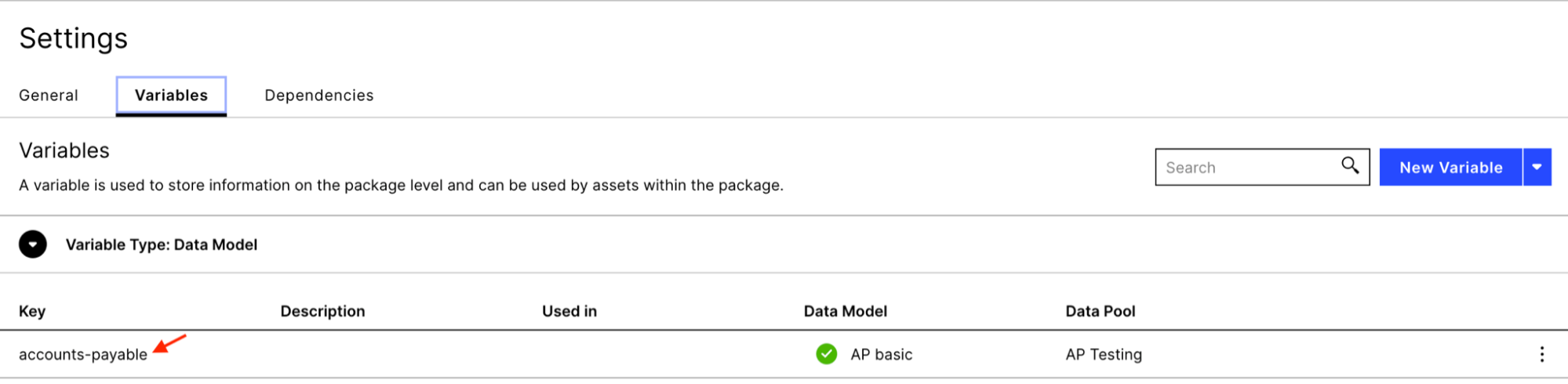
The knowledge model (name: “KM Duplicate Checking” ) contains all the business definitions such as records, attributes, KPIs, variables and filters, and should be aligned with the underlying data model. By default, all definitions are based on the SAP ECC standard A/P connector. Any deviations need to be customized.
These are the variables and attributes that should be correctly defined at a minimum so that the app is able to generate results via the ML sensor:
Object | Standard definition |
|---|---|
INVOICE_ITEM_TABLE | BSEG |
INVOICE_HEADER_TABLE | BKPF |
VENDOR_MASTER_TABLE | LFA1 |
INVOICE_VALUE | WRBTR |
INVOICE_REFERENCE | XBLNR |
INVOICE_DATE | BLDAT |
VENDOR_NAME | NAME1 |
ACTIVITES_TABLE | _CEL_AP_ACTIVITIES |
VARIABLE_REVERSE_ACTIVITY | Reverse Invoice |
VARIABLE_CREDIT_MEMO | Credit Memo |
Invoice Record | ${INVOICE_ITEM_TABLE}."MANDT" || ${INVOICE_ITEM_TABLE}."BUKRS" || ${INVOICE_ITEM_TABLE}."BELNR" || ${INVOICE_ITEM_TABLE}."GJAHR" || ${INVOICE_ITEM_TABLE}."BUZEI" |
Configuring the sensor
The Duplicate Checking ML Sensor (name: “Sense Duplicate Invoices”) is the core of the app. The sensor takes the definitions from the knowledge model. Currently, four in-build comparison fields are used:
Vendor name (default: LFA1.NAME1)
Invoice Value (default: BSEG.WRBTR)
Reference Number (default: BKPF.XBLNR)
Document Date (default: BKPF.BLDAT)
The “Reversal Flag” is used to identify invoices which were already reversed (i.e. they are invalid). The reversed status is applied to the whole group if all of the invoices in the group are caught by the statement in the reversal flag. By default, the configuration of this flag is based on the "Reverse Invoice" and "Create Credit Memo" activities. The "Reversal Flag" is optional but recommended to reduce the number of false positives.
Lastly, filters are applied to the invoice scope to reduce the number of documents checked. At least one filter is required to run the sensor. By default, the sensor comes with two filters applied ("FITLER_DUPLICATE_CHECKER_INTERNAL_VENDOR" and "FITLER_DUPLICATE_CHECKER_SHORT_REF"). The knowledge model, however, contains additional predefined filters which may be useful to apply (e.g. "FILTER_DUPLICATE_CHECKER_LEASE" filters invoices that are lease payments).
Whenever making changes to the sensor configuration, save the skill and publish the package to activate the changes.
Note
The sensor is triggered either by a data model load or by publishing of the package once changes to the knowledge model or skill have been made. The returned signals displayed in the sensor logs represent the newly found duplicate groups by the algorithm.
The sensor logs show the progress of the current run.
Tip
The running executions can be also seen by navigating to "Data", "Machine Learning", "Triggered", "Job" under "duplicate-checking". A running execution can be canceled by clicking on the three dots and selecting "Cancel".
Custom matching logic
The section describes above illustrates the standard setup and the default logic, where the algorithm is fully powered by the ML Sensor. For more details on how groups are formed by default, please refer to the Default patterns section.
With version 2.1.0 ( Release Notes), we introduce the flexibility to customize the matching logic. This allows you to:
Define custom patterns that determine a match
Specify a combination of columns to be checked per pattern (e.g. check 5 columns)
Perform more than one fuzzy match per pattern (e.g. 3 exact and 2 fuzzy matches)
Tweak the parameters per fuzzy match (e.g. increase the date range to 30 days)
These customizations are made in the knowledge model of a given package and will overwrite the configuration in the ML Sensor. For a comprehensive guide on defining custom patterns, please refer to the Custom patterns section.
Configuration changes
During implementation and validation, you may want to change the configuration of the Duplicate Invoice Checker. This will trigger background behavior to make sure that there are no conflicts with the prior setup. This section explains the different scenarios that can occur depending on the algorithm versions.
With the old algorithm, compatible with package version 1.X and lower, a clean up of the entire data pipeline is triggered whenever there is a published change in the ML Sensor itself (e.g. adding or removing a filter) or in the knowledge model definitions used in the ML Sensor. This includes the deletion of the Duplicate Invoice Checker related (1) data jobs, (2) tables in the pool and (3) tables in the data model. To remove any loaded tables, a complete data model reload is initiated as well.
The new algorithm, compatible with package version 2.X, completely changes the behavior of how configuration changes are handled. For more information on Duplicate Invoice Checker 2.X, see Release Notes January 2023.
Changing filters or the underlying PQL of filters used in the ML Sensor does not result in a reset of the data pipeline. Instead, already formed groups are kept in the result table, flagged and then filtered out in the view. If the ML sensor notices a filter change, the column “FILTERED_OUT“ in the “DUPLICATE_INVOICES” table is automatically updated to either 1 (“yes, the group should be filtered out”) or 0 (“no, the group should not be filtered out”). At least one document of a given group has to be filtered out by the filters in the ML Sensor to label the entire group as filtered out. Flagged groups with “FILTERED_OUT” = 1 are hidden in the user interface via the view filter “FILTER_REMOVE_FILTERED_OPEN_GROUPS”.
Note
The update of the “FILTERED_OUT“ column is an experimental feature that may not work at all times. In such cases, please manually apply the equivalent filter in the views to hide groups.
Changing the display name of attributes used in the ML Sensor results in the renaming of the respective column in the “DUPLICATE_INVOICES” table.
Changing the PQL definition of attributes used in the ML Sensor does not result in any changes to the data pipeline. The table “DUPLICATE_INVOICES” is simply appended.
Changing the PQL definition of the record identifier used in the ML Sensor results in a reset of the data pipeline and the archiving of the “DUPLICATE_INVOICES” table (see Components and data flow).
Activating augmented attributes
Once the sensor has run successfully and the results are available in the data model, the last step of the installation process is to enable the user feedback workflow by activating augmented attributes. These are special attributes stored directly in the data model to capture user feedback (more information here).
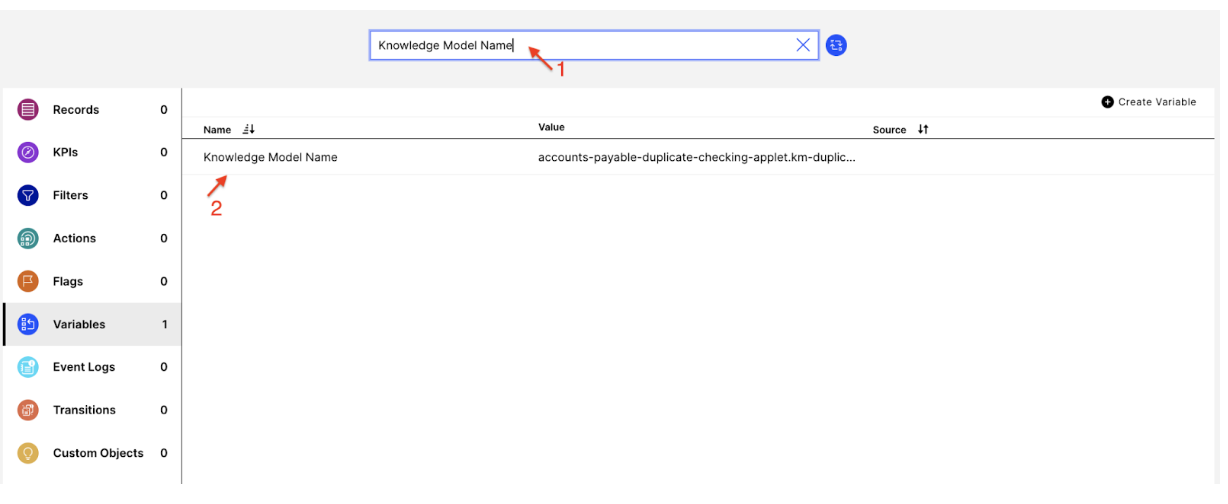
To enable augmented attributes, make sure that the “Knowledge Model Name” variable contains the correct knowledge model key (format: package-key.knowledge-key). By default, the variable should contain the correct value. However, any package key changes, either resulting from copying the package or downloading the app more than once, require you to adjust the variable accordingly. This is necessary as augmented attributes tables are generated once per data model but multiple packages with different knowledge models can write back to the same augmentation table.
Go to the package and click on of the knowledge model, then on “Key”.
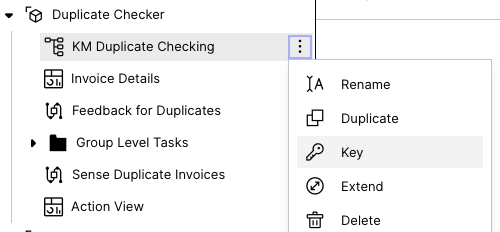
Copy the knowledge model key (including the package key) to your clipboard. Update the “Knowledge Model Name” variable and save the knowledge model. Then publish the package.
 |