ETL Engine
The Celonis ETL Engine transforms your raw source data into Data Models for use in the Celonis Platform. This engine is built state-of-the-art cloud-native technologies and improves the latency for extractions, transformations, and data model loads. The benefits of this engine includes higher data volume processing and increased data freshness. Through horizontal scaling and elasticity improvements, you can get more value out of Celonis by scaling your use cases or adding new ones, without impacting the latency of your existing implementations.
How the ETL Engine works
The ETL Engine is not directly exposed or represented in the Celonis Platform UI. You interact with it by writing SQL transformations and running them in the Extractions Editor or through your data jobs.
For an overview of the SQL syntax used with the ETL Engine, see: ETL Engine SQL Syntax.
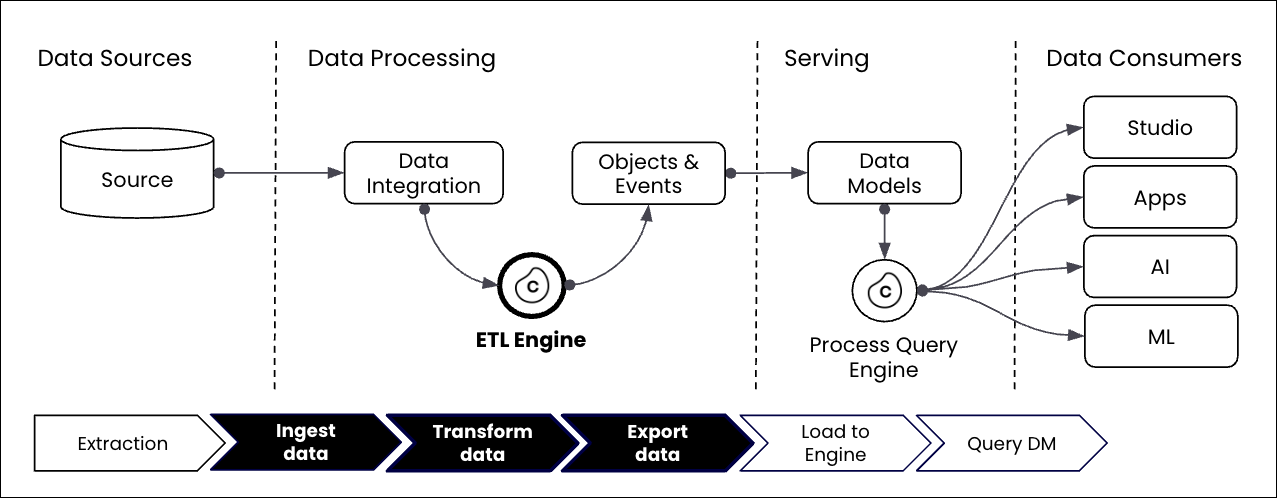
The ETL Engine is involved in all three steps of the Celonis data pipeline:
Extractions: Data is ingested into the Celonis Platform and stored there.
Transformations: The ETL Engine transforms the data into objects and event data using SQL transformations.
Data Model loads: A data model (perspective) is built from the object and events and exported from the data platform before being loaded into the Process Query Engine.
The following illustration visualizes the Celonis data pipeline from a functional architecture and where the ETL engine is located:
Benefits of using the ETL Engine
The benefits of using the ETL Engine include:
Load responsiveness: Ensure optimal performance and maintain it at peak times.
Predictable latencies: Seamlessly accommodate growing data volumes and changing analytical needs. Add new use cases or scale existing ones while keeping predictable and stable data pipeline runtimes for all your Celonis use cases.
Large data volumes: Run ETL workloads for large data volumes with billions of records in new record times (confirmed by internal benchmarks).
Lowest latencies: Fast data processing, enabling near real-time data refresh rates, and enabling operational Celonis use cases.