Push CSV to Data Integration
Pushing large volumes of data to a Celonis data pool using the "Write Data to Table" action in Studio Skills is inefficient because it processes only one row at a time.
For faster performance, you can use an Action Flow to create a CSV file and upload it directly to a data model via the Celonis Data Push API. This method allows you to transfer large datasets in a single step and can be used to build custom data connectors within Action Flows.
The Action Flow is designed to bypass the row-by-row limitations of standard Studio Skills by leveraging the Celonis Data Push API. This batch-processing approach significantly reduces the time required to update Data Models with external information.
Data Retrieval (OneDrive): The flow begins by monitoring a specific cloud storage folder. In this example, the OneDrive "Watch Files/Folders" module is configured to trigger whenever a new CSV is detected.
Variable Initialization (Tools): To simplify maintenance and ensure the flow is portable across different environments, a Set Multiple Variables module centralizes key environment data.
Job definition and metadata (JSON): Before data is sent, the Create JSON module defines the "Push Job" parameters. This tells Celonis how to handle the incoming data:
API execution (HTTP): The data transfer is managed through three distinct HTTP requests to the Celonis Data Push API.
Verification (Data Integration): Once the flow finishes, the results are verified within the Data Integration tab. A new Data Job using a "Global (no data connection)" source is used to inspect the table via a transformation or a simple SELECT * query in the Schema Explorer.
 |
Below you will find the step-by-step guide for configuring each module of the above Action Flow.
In the example provided above, the data to push is gathered from a CSV file uploaded in OneDrive. The screenshot on the right shows how this module has been configured.
 |
Configuration:
Action Flows Module: OneDrive
Action: Watch Files/Folders
Connection: connect to your OneDrive account
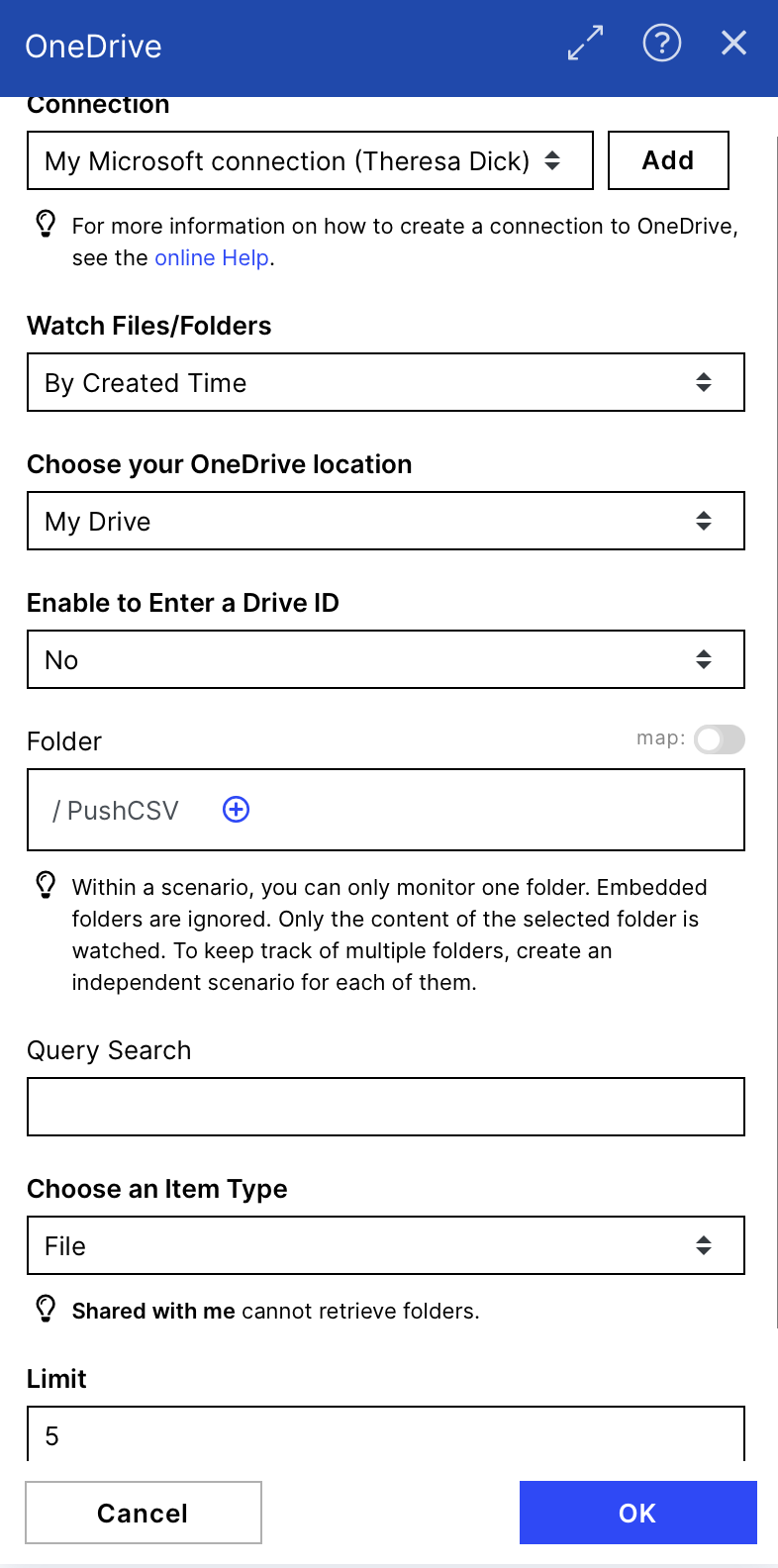
Folder: Navigate to the Folder you want to use for the CSV files to upload
Limit: Decide how many CSV files can be uploaded at the same time maximum to be sent to the data pool
In the demo we used the following CSV called pushSO.csv. If you want to use it for testing purposes, feel free to download it and put it in your OneDrive folder:
 |
As soon as (CSV) files are detected in the folder, we need to download them to use the file's data in the following modules. The screenshot on the right shows how the download module has been configured.
 |
Configuration:
Action Flows Module: OneDrive
Action: Download a File
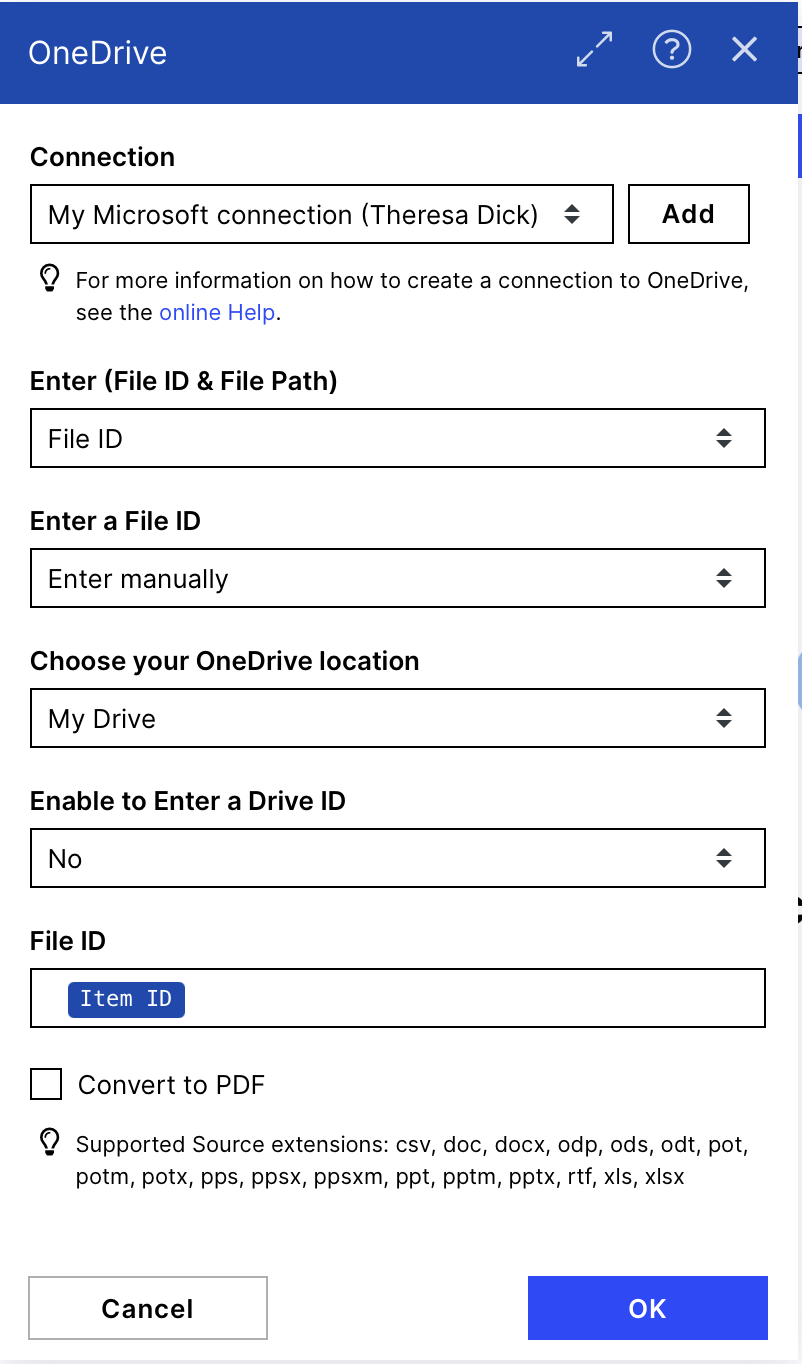
Connection: connect to your OneDrive account
Enter (Filed ID & File Path): File ID
File ID: choose the Item of the module before called: Item ID
 |
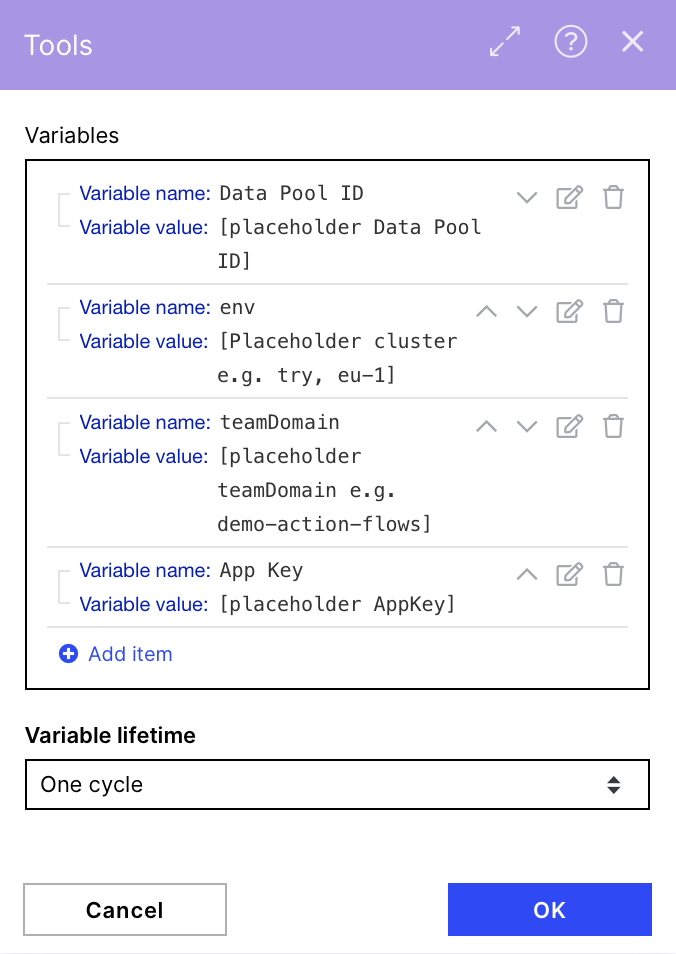
To make customizing the URL in the HTTP modules easier, we save our Data Pool ID, cluster, teamDomain and the App key we use as variables to reuse them and have a central point for maintenance.
 |
Configuration:
Action Flows Module: Tools
Action: Set multiple variables
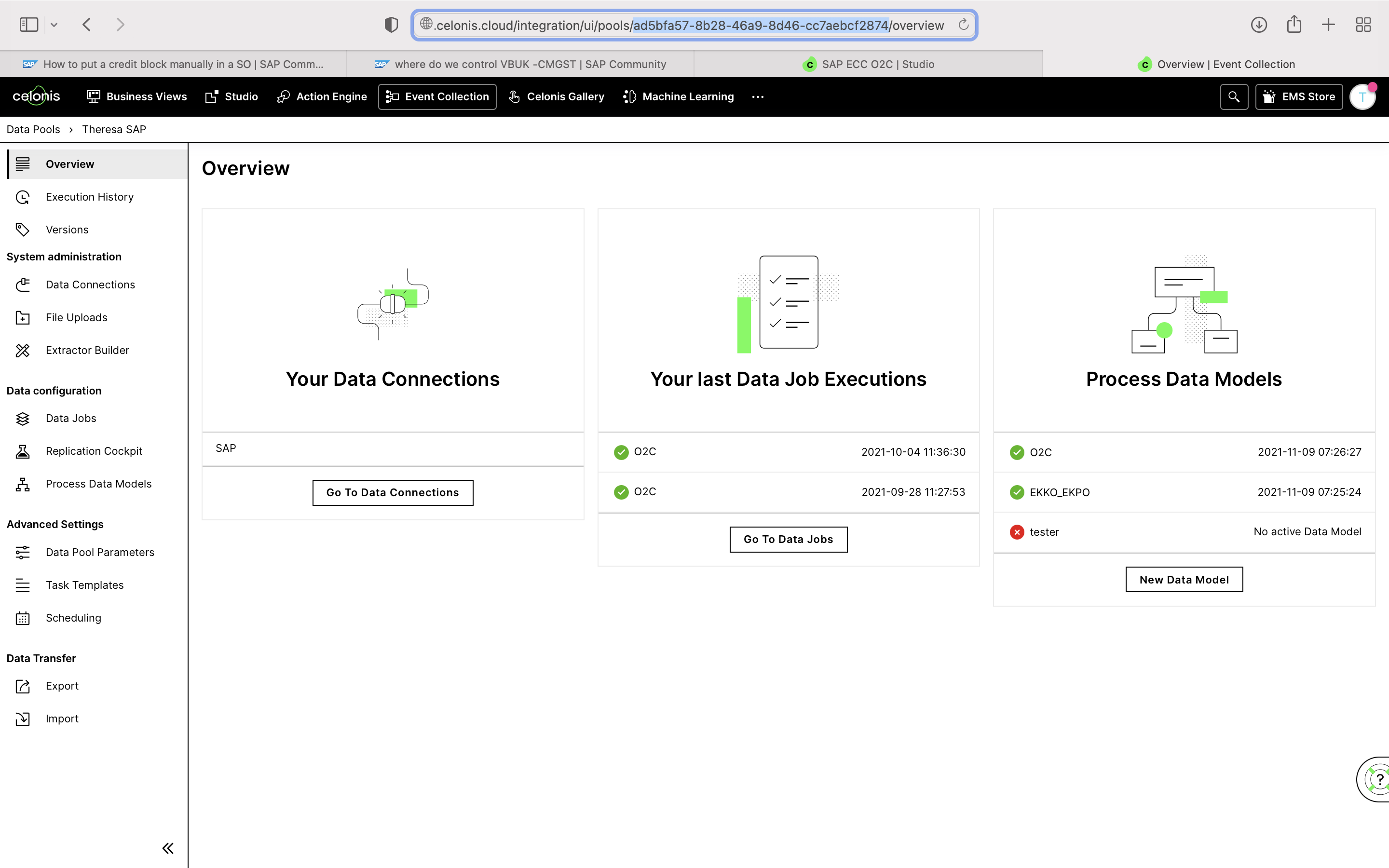
dataPoolId: Defined by user (this is the unique identifier for the data pool to which you want to push the CSV of data. You can locate the Data Pool ID from the URL when opening this specific Data Pool of your Celonis Platform team.
 |
env: your cluster e.g. try, eu-1...
teamDomain: your team domain e.g.demo-action-flows
Use env with domain name for URL
The URL address of an environment is composed of the env and teamDomain values. Using examples above this could be for instance:
https://demo-action-flows.eu-1.celonis.cloud/*
AppKey: e.g.: GjV6ODBvghgv6r76r0YzkyLTkxZwjbflqjwhebfljwhebfqjhebfwlV5TEVCcjMzAHBFK0F8TXdGBTlqBWFGkBJobEG2K3ZqTUyxL9RhnllsVPNk
Make sure to grant the proper permissions for the data pool to the App Key. See the note below.
 |
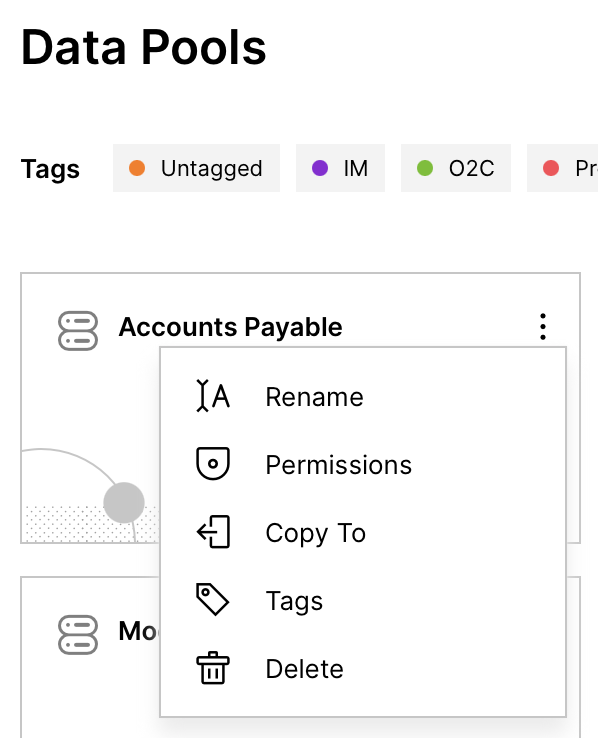
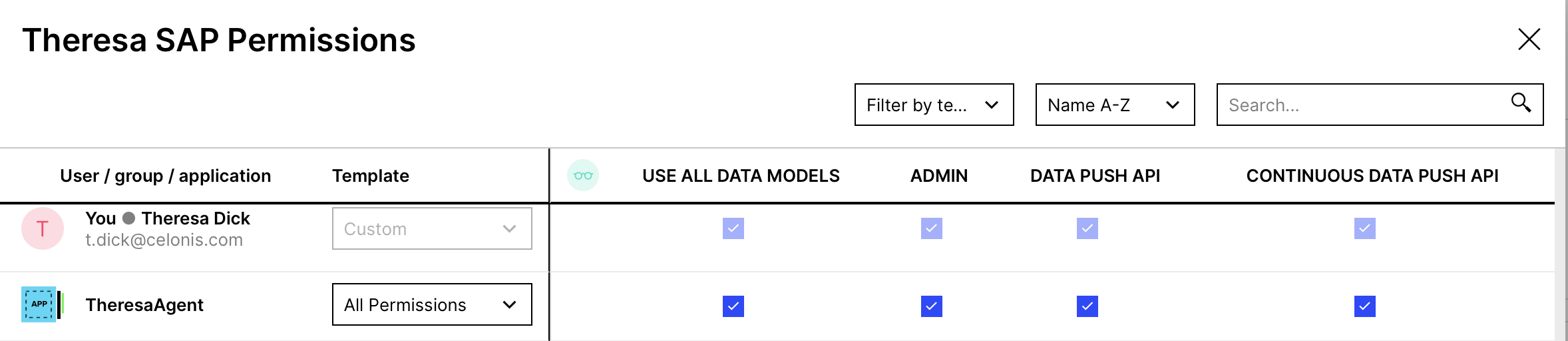
Admin Rights
Make sure to have all rights on the specific data pool with that application key by navigating to Permissions of the Data Pool and ticking all boxes:
 |
 |
Once you have configured the CSV, you can begin defining the requirements for pushing the file to your chosen Celonis data model. We use the JSON module to set the required inputs for the Data Push API.
 |
Configuration:
Action Flows Module: JSON
Action: Create JSON
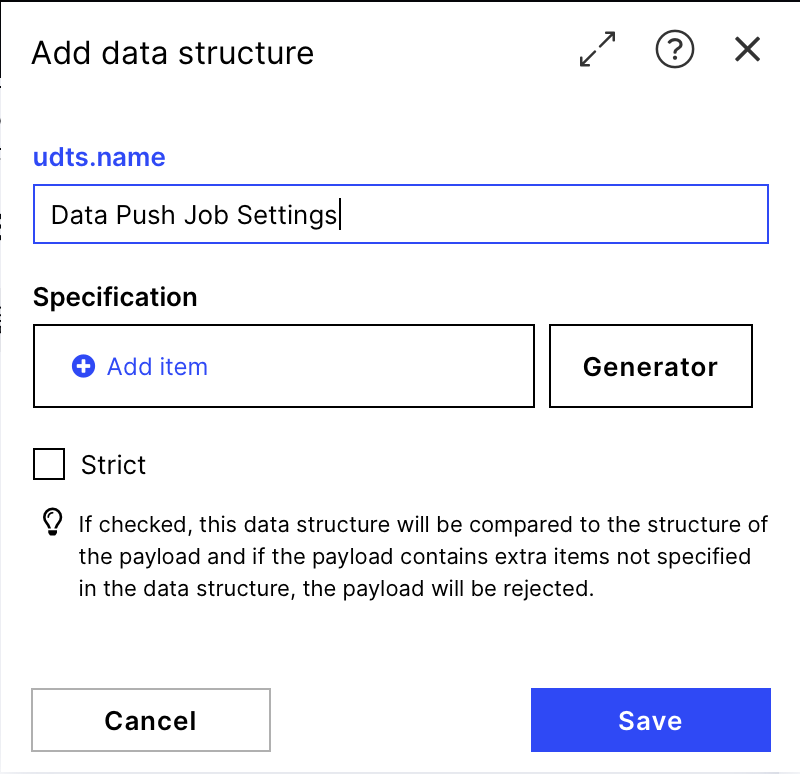
Data structure: Add a new data structure that will define the settings of the data push job.
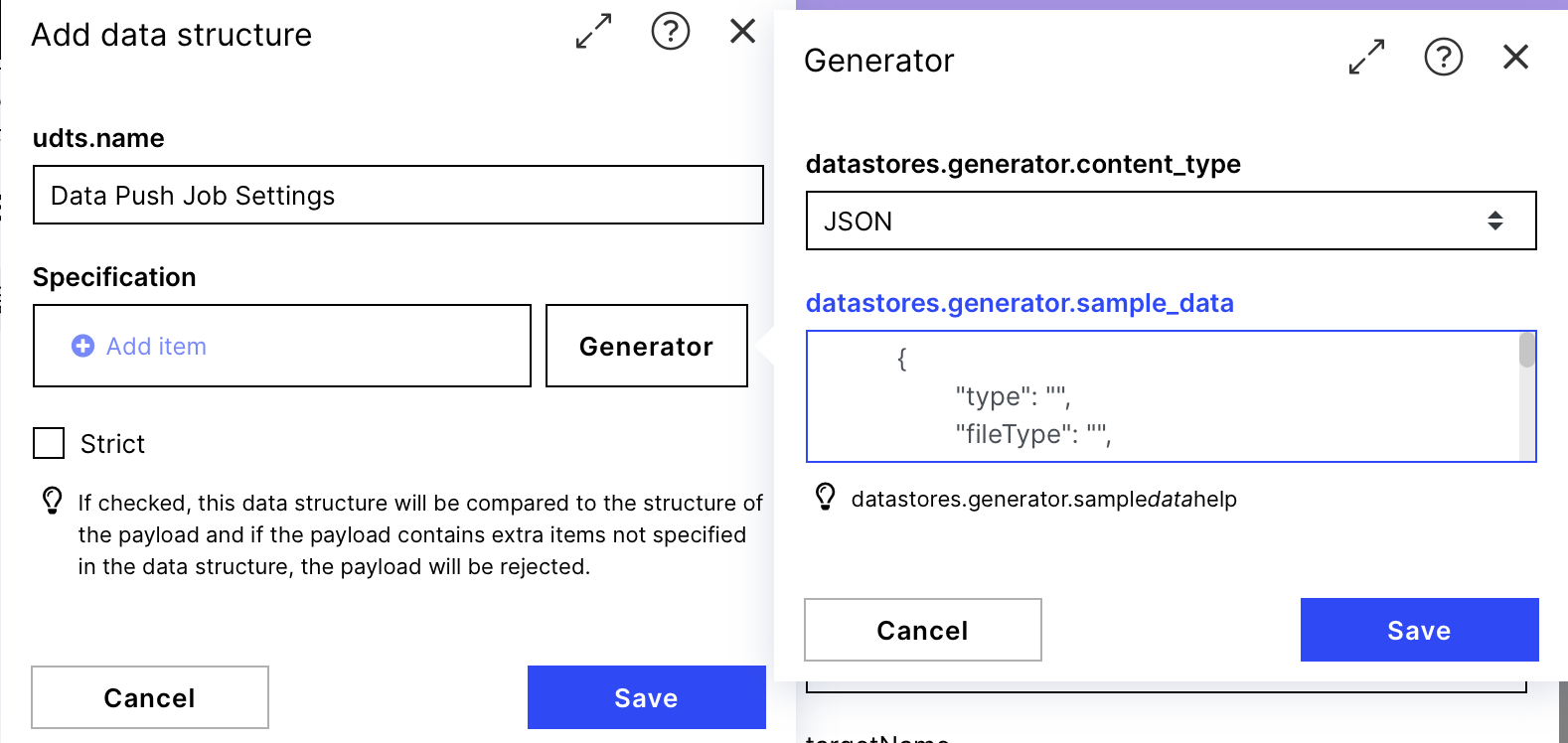
Generator:
datastores.generator.content_type:JSON
datastores.generator.sample_data:
{
"type": "",
"fileType": "",
"dataPoolId": "",
"targetName": "",
"csvParsingOptions": {
"decimalSeparator": "",
"separatorSequence": "",
"lineEnding": "",
"dateFormat": ""
}
}After generating the data structure with the Generator by clicking the save button compare it to the structure provided in the screenshot on the right. If it looks the same, you are good to go saving and filling the structure.
 |
 |
 |
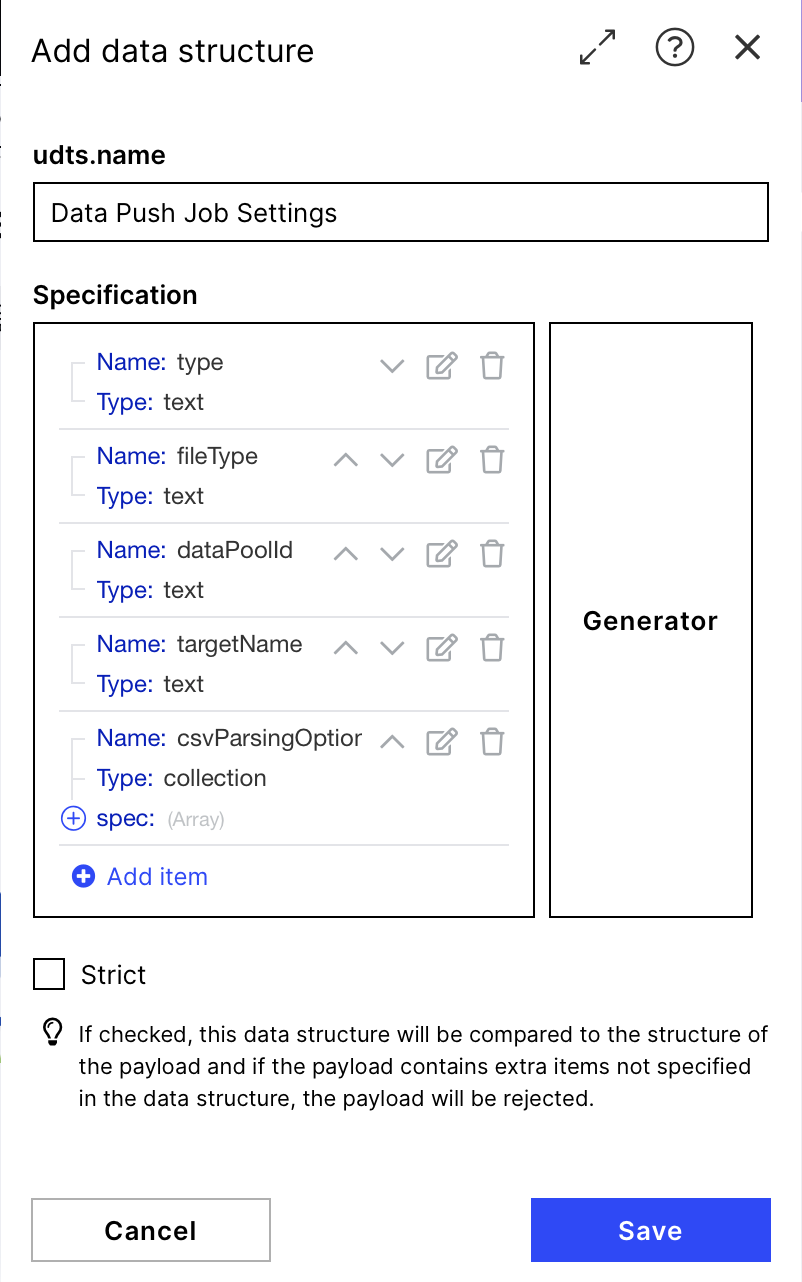 |
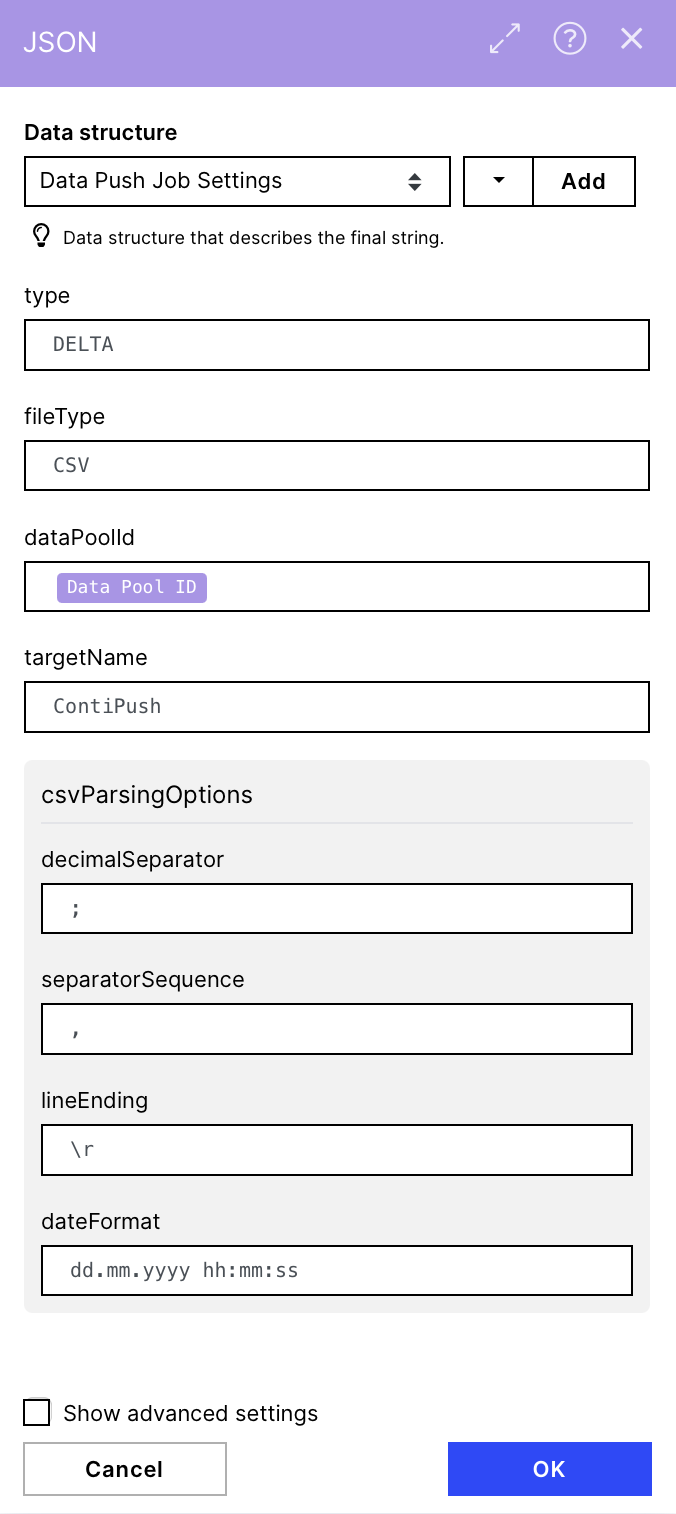
If the data structure was configured correctly, your "Create JSON" module should now look much like the screenshot on the right. You should provide the required inputs for the fields defined in your data structure. See below:
type: DELTA (or REPLACE)
fileType: CSV
targetName: Defined by user (this is the name of the table that will be created when you push the CSV of data to the Celonis data pool)
Note
Type in the correct name here if you want to push into an existing table!
dataPoolId:the variable item Data Pool ID
csvParsingOptions:
decimalSeparator : ;
separatorSequence: ,
IMPORTANT
Make sure you choose the separator of the CSV files which will get uploaded to your drive. It is essential that every CSV you upload in the Drive uses the same separator symbols which you have to define here; otherwise, you won't get the different columns but one column with all your data. If you don't know what the suitable CSV for these settings should look like, have a look at the example CSV we provided before.
lineEnding : \r
dateFormat: dd.MM.yyyy hh:mm:ss
 |
Warning
The following instructions for modules 5 - 8 can be skipped as they are preconfigured in the Marketplace blueprint. Please go on with step 9.
Nevertheless, the documentation can support you if you face any problems or want to understand what is happening.
Now that you have configured the JSON string containing our job settings, we can create the data push job. We will use the HTTP module and the Celonis Data Push API for this. You can find the corresponding documentation here.
 |
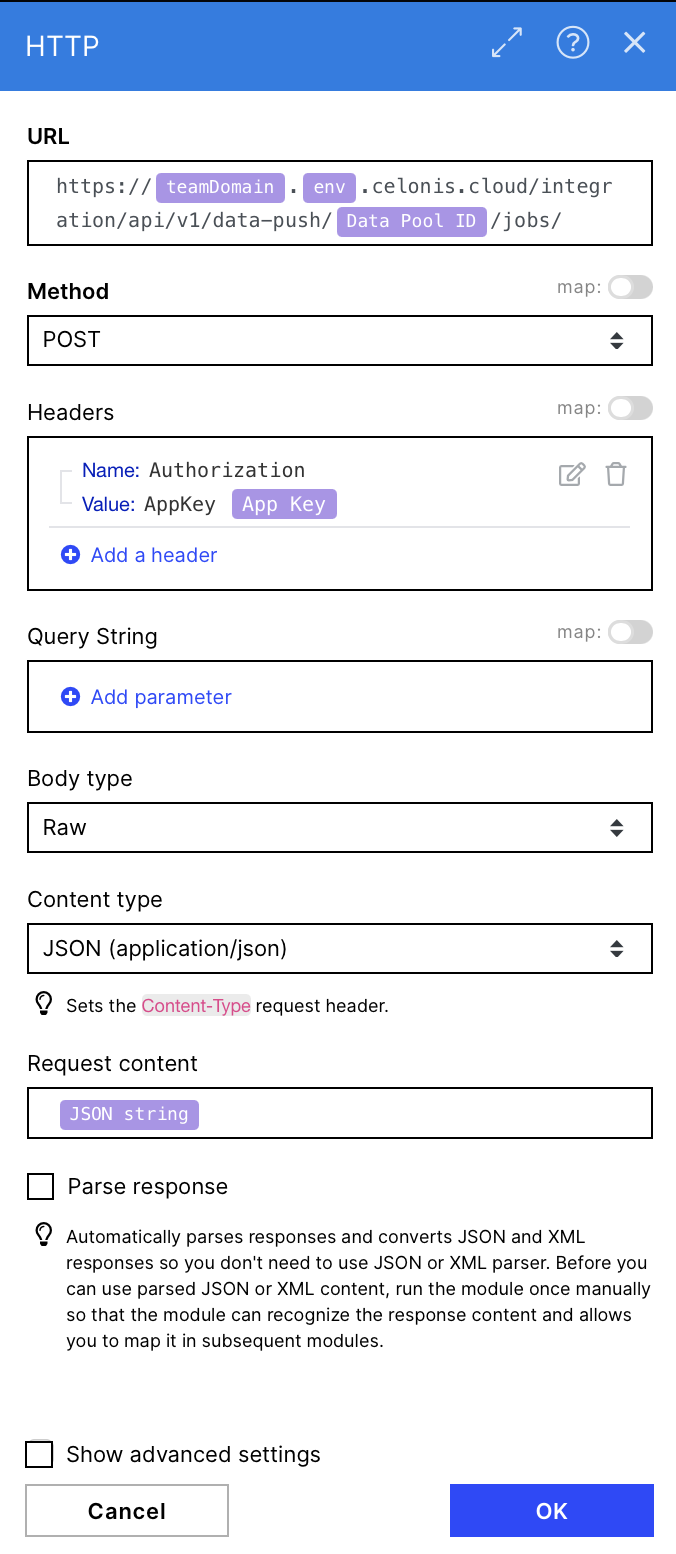
Configuration:
Action Flows Module: HTTP
Action: Create Make a request
URL: https://{{21.teamDomain}}.{{21.env}}.celonis.cloud/integration/api/v1/data-push/{{21.`Data Pool ID`}}/jobs/
Method: POST
Headers: Create a header that contains an application key for accessing the relevant data pool
Name: Authorization
Value: AppKey {{21.`App Key`}}
Body type: Raw
Content type: JSON (application/json)
Request content: "JSON string" from module 3 (JSON)
Warning
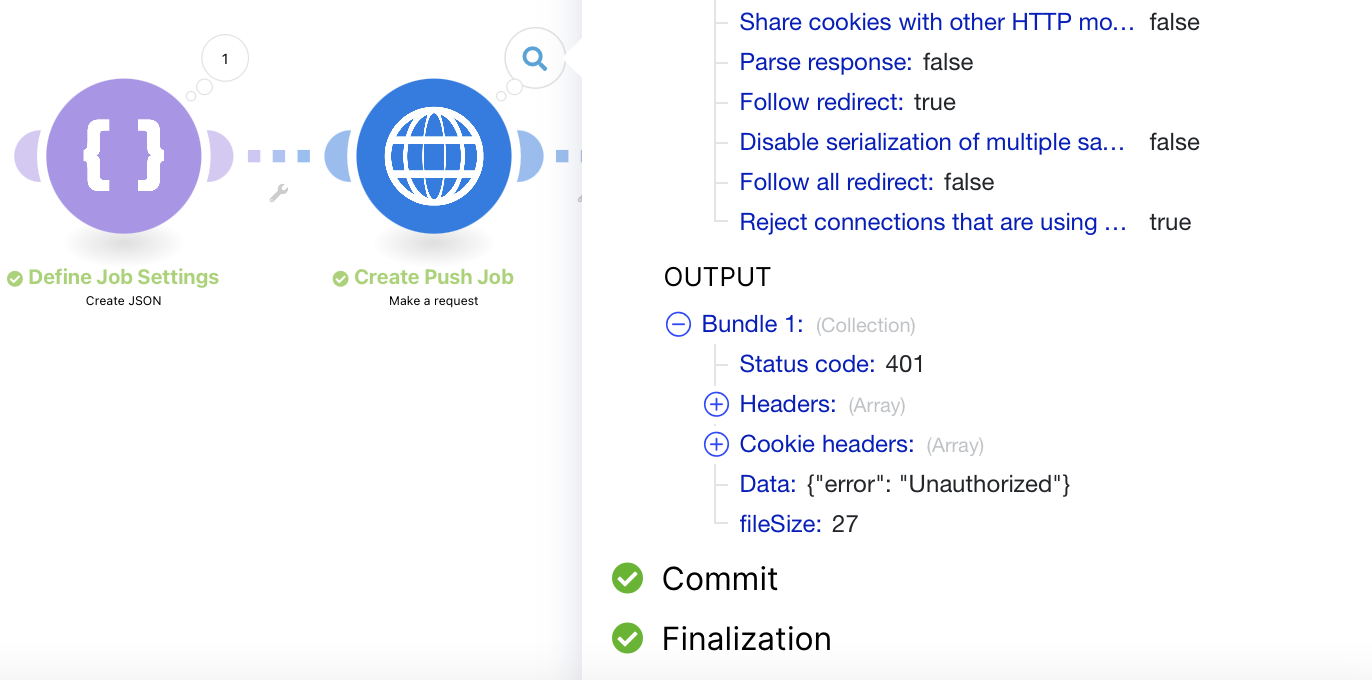
Make sure to check the Status codes of the HTTP modules! The green checkmarks just indicate that the module got a response, even if the response was that you do not have the proper permissions. To ensure that the module has the intended behavior, you have to look at those status codes. If you run the flow, you can find them by clicking on the bubble with the 1 on top of the module. There is a section called 'OUTPUT.'
The Status code 200 or 201 indicates that everything worked out. Status codes like 401 indicate a problem like being not authorized. When getting a 401, make sure you grant the correct permissions to your Application Key (find instructions in the warning before).
 |
 |
Next, you will parse the ID from the first HTTP module's data output so it can be leveraged in the next step. We use the "Parse JSON" action for this step.
 |
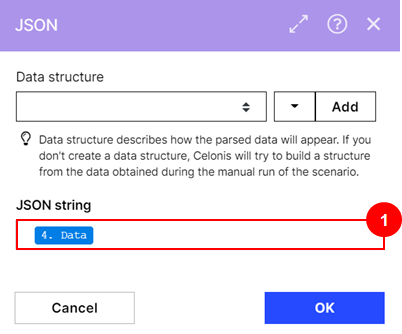
Configuration:
Action Flows Module: JSON
Action: Parse JSON
(1) JSON String: "Data" from module 4 (HTTP)
 |
In this step, we push the CSV to the Celonis data model. Again, we use the HTTP module to make a request with the required configurations. See the screenshot on the right for reference.
 |
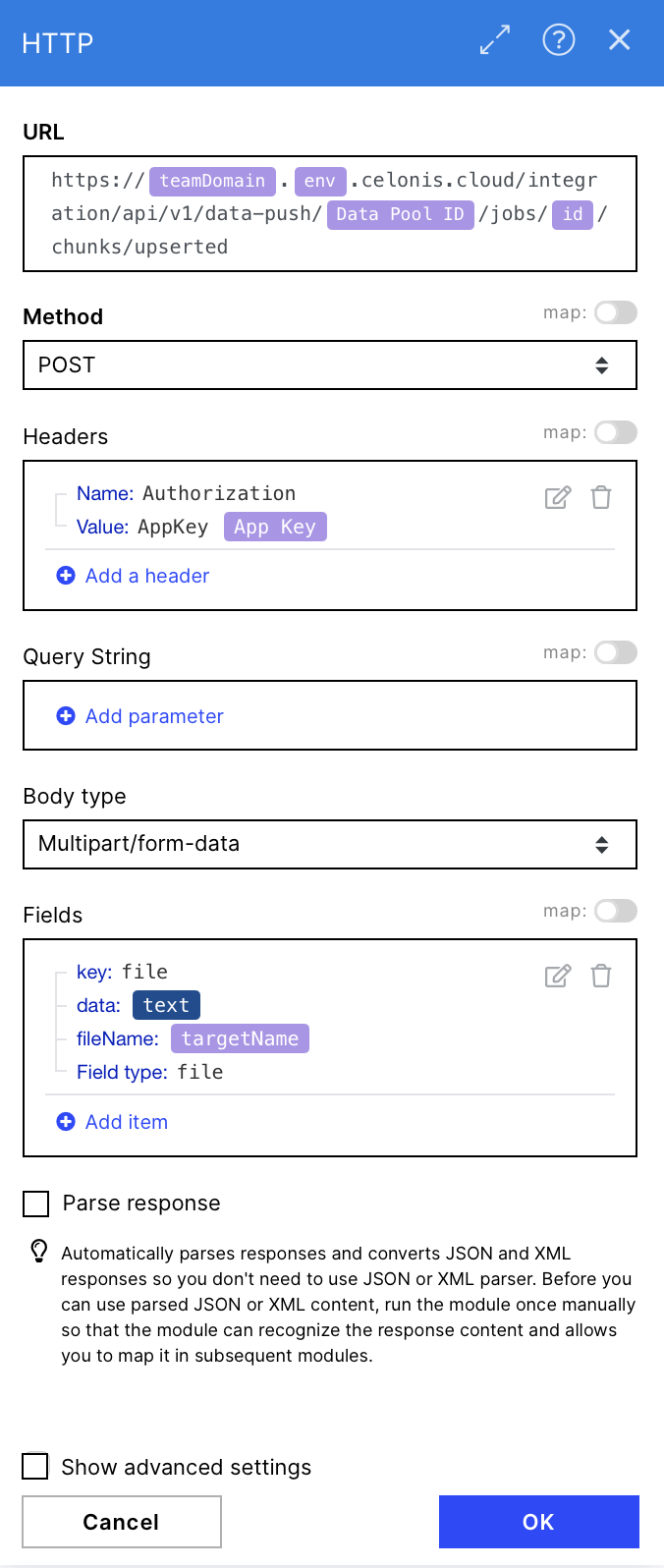
Configuration:
Action Flows Module: HTTP
Action: Make a request
URL: https://{{21.teamDomain}}.{{21.env}}.celonis.cloud/integration/api/v1/data-push/{{21.`Data Pool ID`}}/jobs/{{5.id}}/chunks/upserted
Method: POST
Headers: Create a header that contains the application key used before for accessing the relevant data pool (same AppKey as in module 4)
Name: Authorization
Value: AppKey {{21.`App Key`}}
Body type: Multipart/form-data
Fields:
key: file (changing this, seems to cause an error)
data: "text" from module 2 (Create Advanced CSV)
fileName: "targetName" from module 3 (Create JSON)
Field type: file
Note
You may need to run module 5 (Parse JSON) once for its outputs to be available for use in module 6.
 |
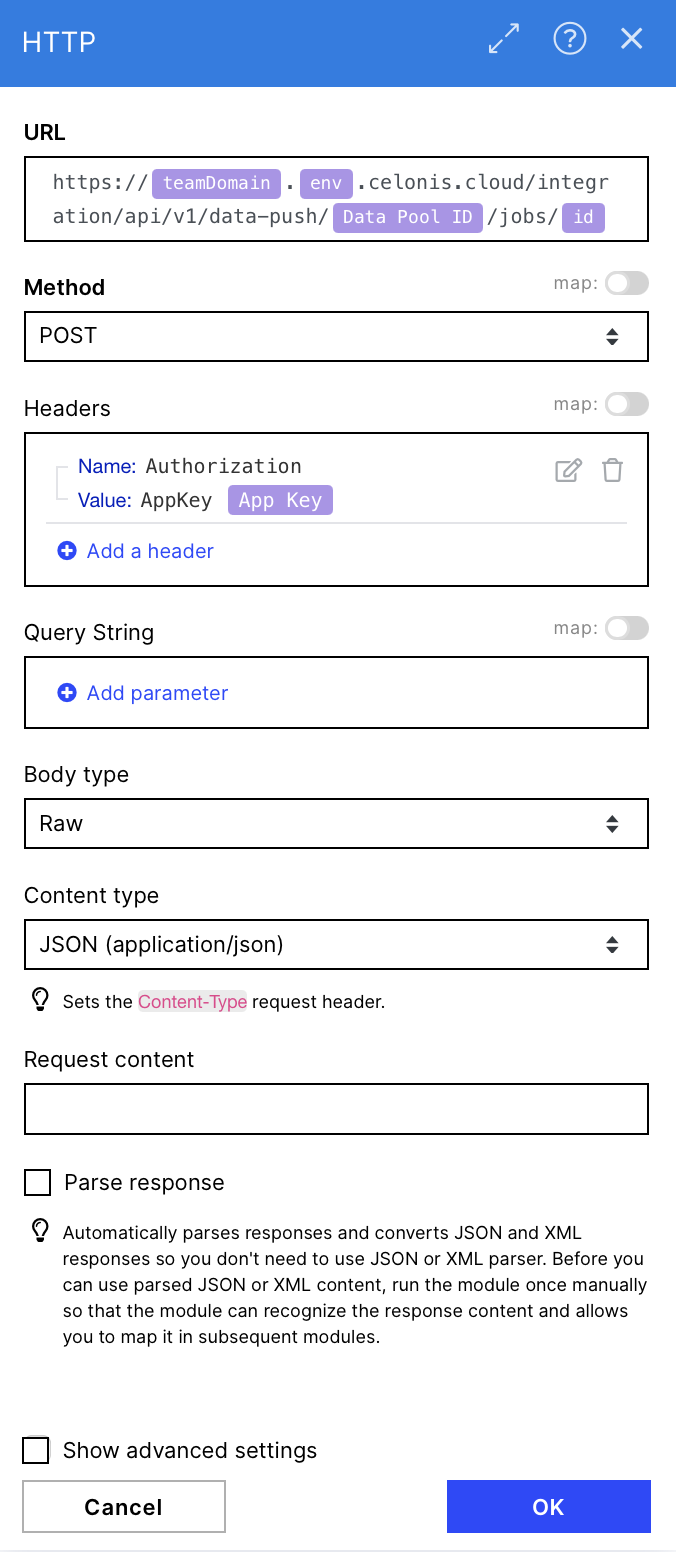
The final step is to confirm and execute the data push job. See the required configuration in the screenshot on the right.
 |
Configuration:
Action Flows Module: HTTP
Action: Make a request
URL: https://{{21.teamDomain}}.{{21.env}}.celonis.cloud/integration/api/v1/data-push/{{21.`Data Pool ID`}}/jobs/{{5.id}}
Method: POST
Headers: Create a header that contains the application key used before for accessing the relevant data pool (same AppKey as in module 4)
Name: Authorization
Value: AppKey {{21.`App Key`}}
Body type: Raw
Content type: JSON (application/json)
 |
Save and run the Action Flow. After a successful run you can check your results:
Navigate to Data Integration.

Choose the Data Pool you sent Data to (he one from which you got the ID before)
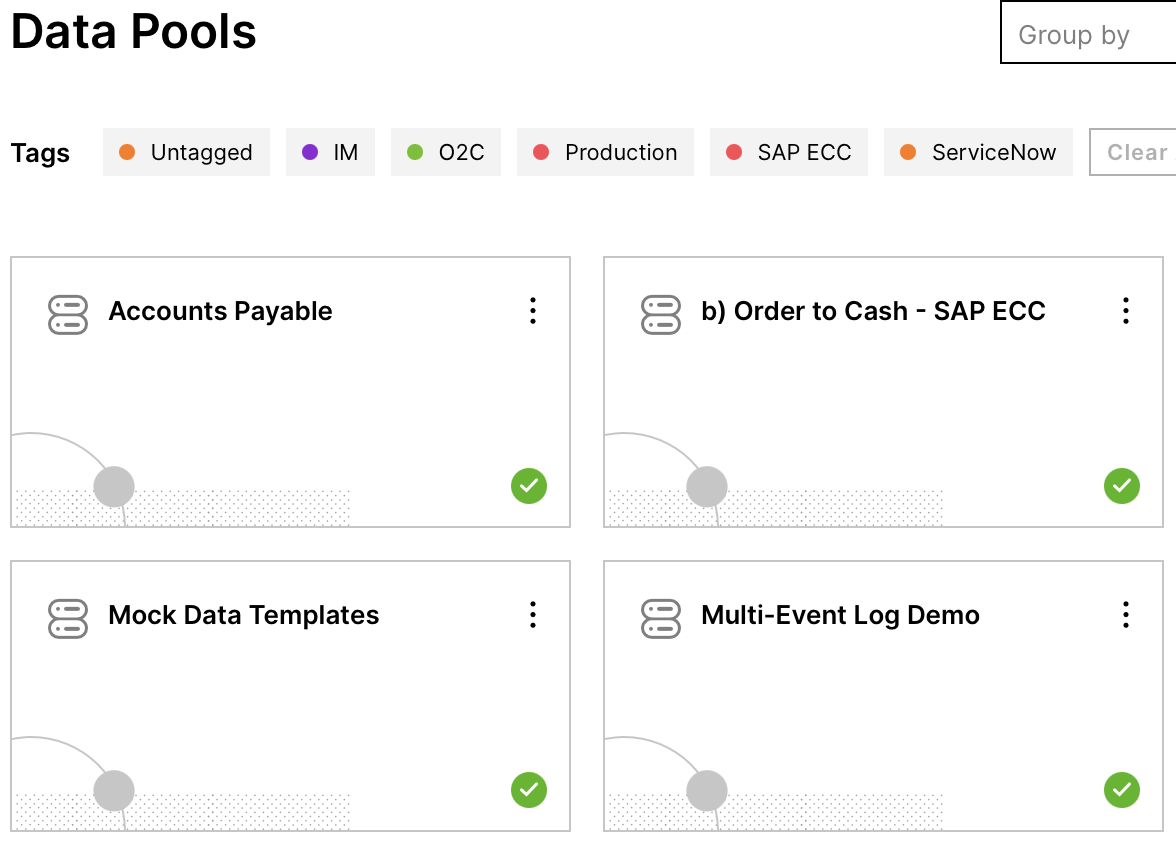
Click on Data Jobs in the sidebar on the right

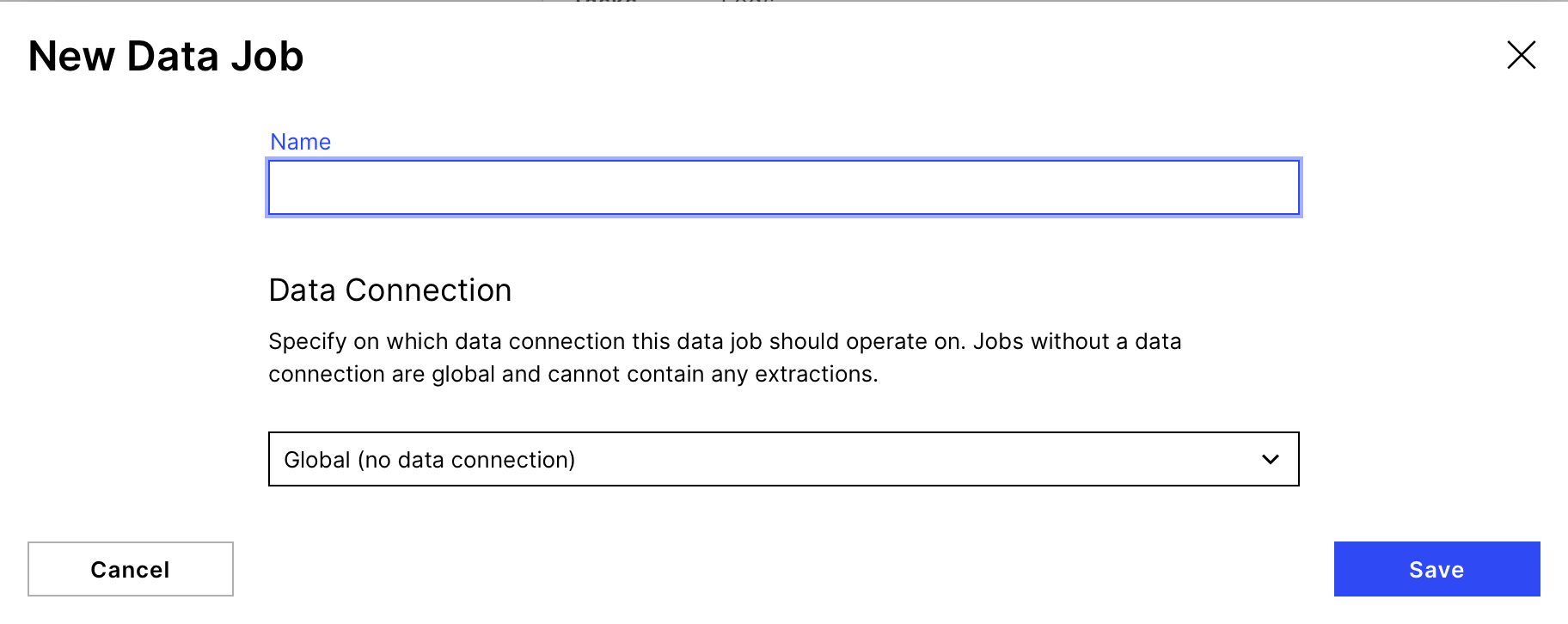
Create a New Data Job

Make sure to choose "Global (no data connection)" as Data Connection
Add a new Transformation within the new Data Job
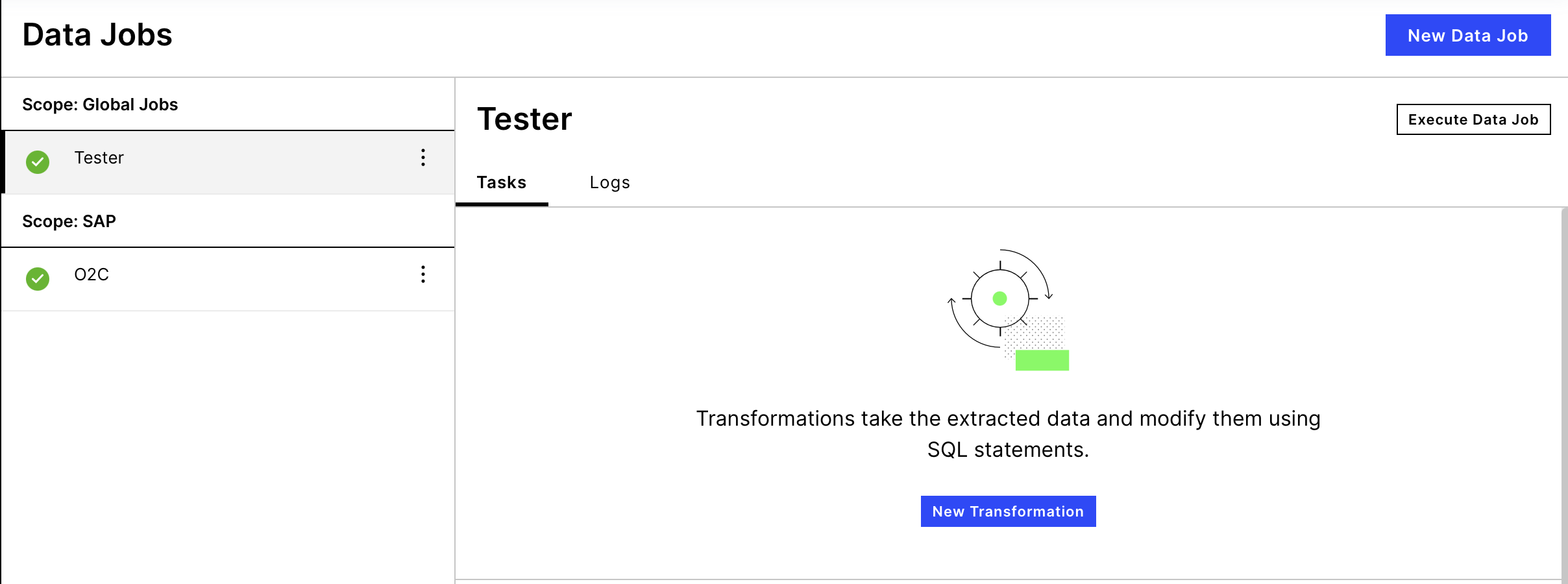
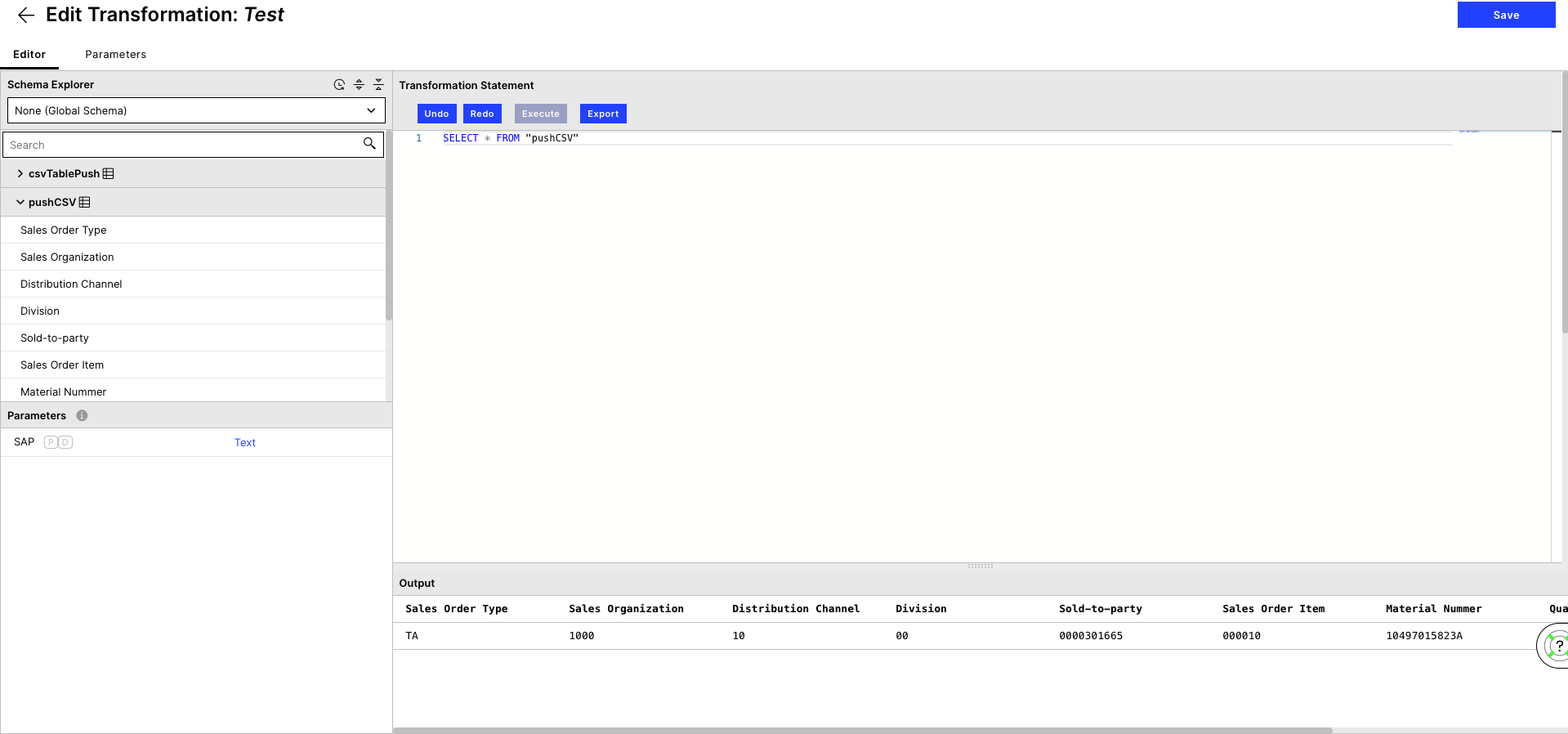
After choosing a name, you should see the sent table with the specified name in the Schema Explorer on the right. When unfolding the table, you should be able to see the columns.
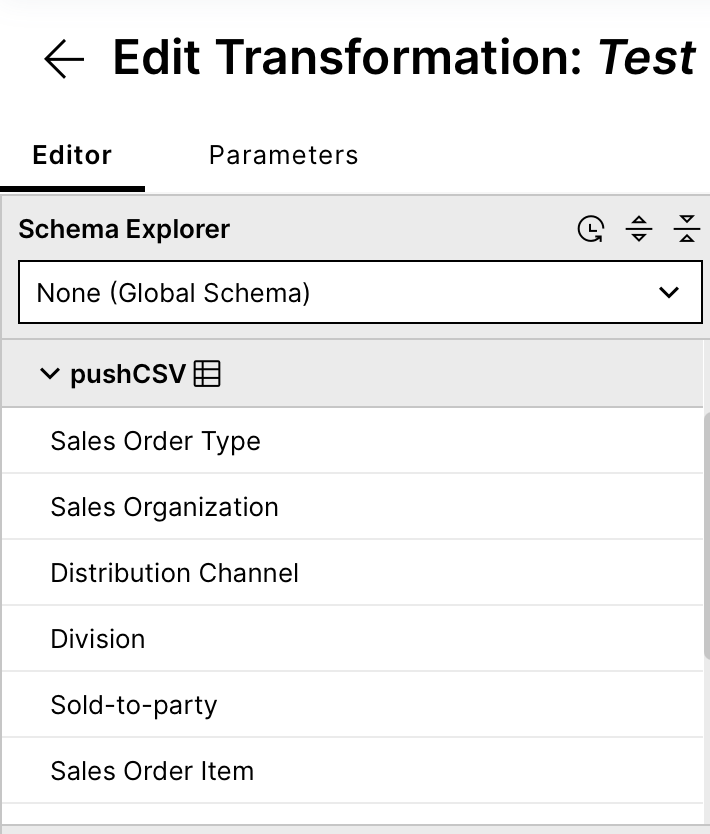
Note
When there is only one column with all headings inside, the column separator in module 3 (Define Job Settings) might have been chosen wrong.
To have a look at the data type in SELECT*FROM ["name of your table"] (in our case that's "pushCSV"), mark it and click execute. You should now be able to see the table with your data at the bottom