Creating extraction tasks using the Extractions Editor and AI Assistant
Privacy Statement and Customer Consent
The Extractions Editor is designed for read-only access and supporting queries intended to retrieve data without modification. It is configured to limit access to resources within the user’s existing permissions.
You agree to follow best safety and security practices and use a least privileged database user in Celonis Platform to connect to your cloud or on-prem databases and least privileged operating system user to run queries on your database systems.
You accept responsibility for your input queries and data transmissions to the AI Assistant, including any impacts on your infrastructure and data.
Extraction tasks allow you to select the data tables to be extracted from your source system (and imported into the Celonis Platform). You can now create, validate, and preview extraction tasks for JDBC source systems using the Extractions Editor and AI Assistant, allowing you to dynamically write SELECT SQL queries and use your source system's SQL dialect.
For more information about the Extractions Editor and AI Assistant see: Extractions Editor and AI Assistant overview
And for a video demo of these features:
Before using the Extractions Editor and AI Assistant, you must complete the following prerequisites:
JDBC extractor: If you're currently connecting to your source system using the JDBC extractor, you must update the extractor to version 3.0.0 in order to use the Extractions Editor and AI Assistant.
For more information, see: Updating JDBC extractors.
On-premise extractor: If you're currently connecting to your source system using an on-premise extractor, you must update the extractor to the latest version in order to use the Extractions Editor and AI Assistant.
For more information, see: On-premise extractors.
AI Assistant: You must enable the AI Assistant in your Admin settings.
For more information, see: AI Settings.
To create extraction tasks using the Extractions Editor and AI Assistant from your Data Pool diagram:
Click Data Jobs and select an existing data connection scope.
In the extraction row, click + Add.

Enter an extraction task name, select SQL editor, and then click Save.
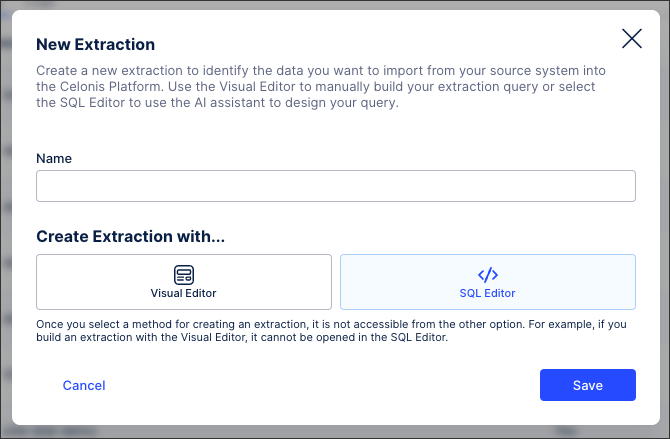
The SQL editor loads.
Using the Extractions Editor and AI Assistant, configure your extraction task by writing an SQL statement.
For more information about the features available here and the task settings, see: Extraction task configuration and settings.
Click Save.
The extraction task is saved and can be managed in the following ways:
You can manage existing extraction tasks by clicking Options.
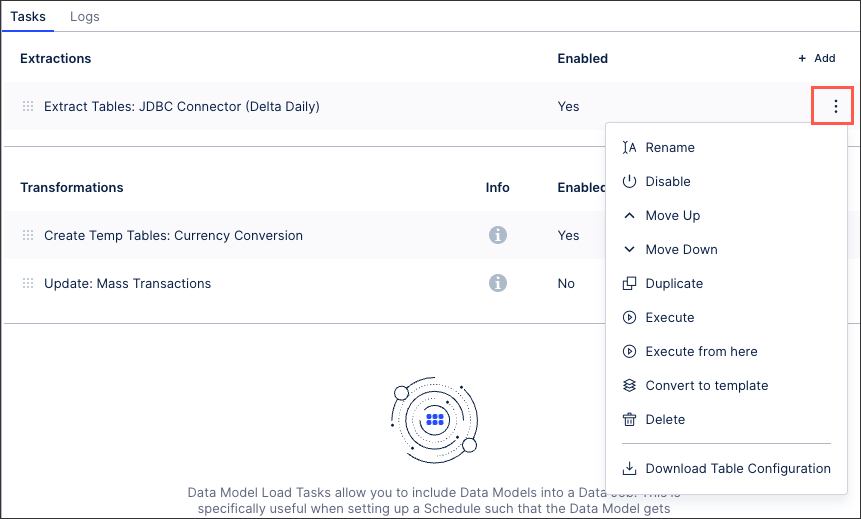 |
You have the following options here:
Rename: Update the name of the extraction task.
Enable / disable: Control whether the extraction task should be enabled or disabled for executions.
Move up / down: Change the order in which this task is performed in a full execution.
Duplicate: Create a copy of the extraction task in the existing data job.
Execute: This allows you to manually execute just this task on demand. For more information about executing data jobs, see: Executing data jobs.
Execute from here: This allows you to manually execute this and all following tasks on demand. For more information about executing data jobs, see: Executing data jobs.
Convert to template /copy to regular task: The task becomes a template and can be added to other data jobs or used to extend the template. If the task is already a template, you can create a regular task from it. For more information about task templates, see: Creating data job task templates.
Delete: This deletes the task and all associated content, with no recovery possible.
Download table configuration: This gives you offline access to a zipped file containing any relevant Excel workbook copies of your table configuration.
Extractions Editor and AI Assistant features
When using the SQL editor and AI Assistant to create your extraction tasks, the following features are available:
Schema explorer: The schema explorer allows you to search for and select tables from your Data Model.
Target table configuration: This allows you to setup and configure the table into which your extracted data will be imported. You can assign primary keys and select if the column should be pseudonymized. It’s mandatory to provide the name for the table.
Validate SQL: This validates your current SQL statement and either confirms that it would successfully run or highlights errors for you to address. Please note, this feature is still under development and will be updated further soon.
Preview SQL: This runs your current SQL statement and gives you a preview of the extraction tasks and their associated logs. This is not a complete extraction, we only run the query with a limit of 100 records to ensure the query works and can fetch the data, once extraction is saved and executed.
Download SQL: This gives you offline access to your SQL statement as a .sql file.
AI Assistant: To generate an SQL query using the AI Assistant, you select the tables you would like to include in the query and then type prompts. We recommend keeping the selection limited to 4-5 tables for optimal performance.
Undo / redo: Efficiently undo or redo the most recent changes to your SQL statement.
The available extraction settings depend on the source system that you're connecting to.
Debug mode: Once enabled, the debug mode provides detailed log information for the data extraction job and will be displayed in the execution logs. This allows for more transparency and easier troubleshooting. This mode is active for three days and the logs created are then deleted.
Convert to a delete job: Converts the extraction task in the data job to a deletion task. All records found by this extraction task will be deleted from your data pool.
Delta load configuration: Select from either:
Option A - Standard: The delta load will be cancelled, when metadata in your source system changes (i.e. new columns) compared to already extracted data in the IBC. Metadata changes will not be ignored. A full reload or manual changes of your table is necessary to clear this conflict.
Option B - Including metadata changes: The delta load will include metadata changes (i.e. new columns) and run through with a warning. Only delta loaded rows will include data for the newly added columns. Rows which are not part of the delta load will have the newly added columns nullified. This can lead to inconsistency in your data. A full load is recommended for data consistency.
Connector parameters: The following connector parameters can be configured:
Batch size: Allows specifying the batch size (in records) for one extraction request.
Max string length: Allows the modification of the default length (80 characters) of String-type columns.This is configured using the parameter: MAX_STRING_LENGTH
Binary data type handling: Table column with binary data type can be represented in two ways: UTF- 8 or HEX_NOTATION. Depending on the value specified here the binary value will be converted.
Change default metadata source: Depending on your database, you can select from:
DRIVER_METADATA: This metadata source is supported by all source systems and mostly it is the default one. Here the driver internally runs the metadata Query against the source system and fetches the result set.
SAMPLE_QUERY: This metadata source is supported by all source systems. This also works the same as driver metadata, only the query used is different.
INFORMATION_SCHEMA: This metadata source is supported mainly by Oracle system. And it's a default metadata source for Oracle 11g.
PG_CATALOG: This metadata source is supported by Amazon Redshift. And it's a default metadata source.
Limit total number: Set the maximum number of records to be extracted per job.
When using the Extractions Editor and AI Assistant, we recommend the following best practice:
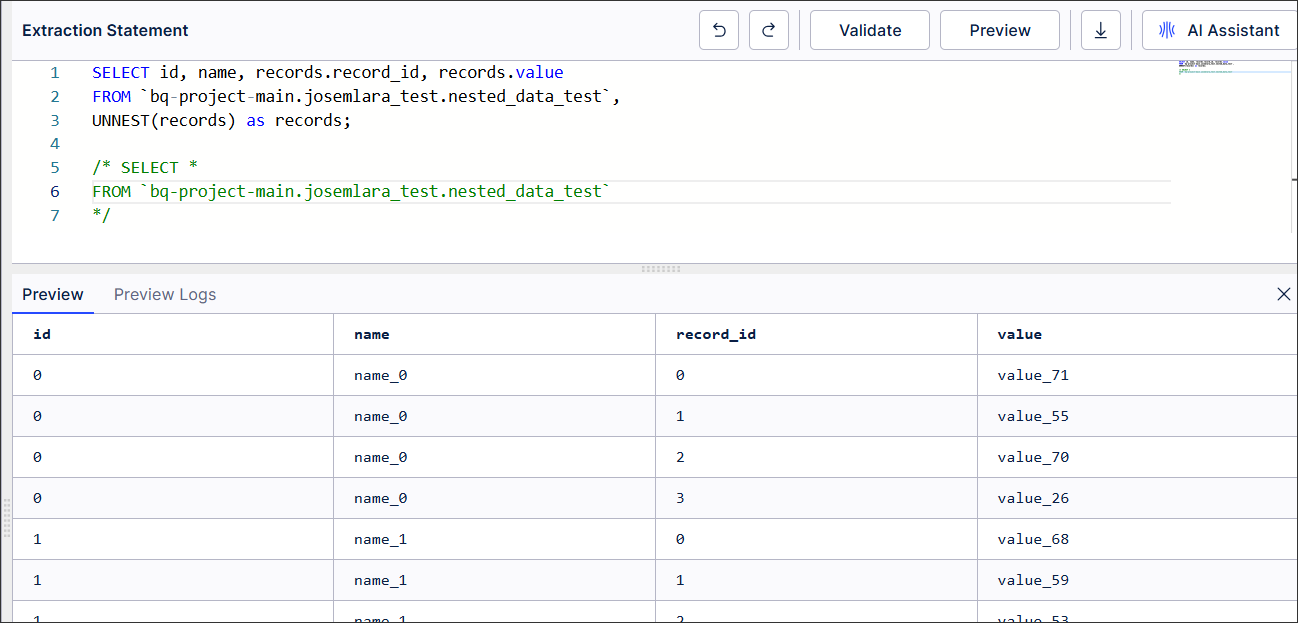
Extracting nested records from BigQuery
You can place your own free-form SQL into the Extractions Editor and then perform an extraction. Initial testing below, was using the UNNEST Keyword in the BigQuery SQL Syntax and verifying the data was loading in the desired format.
 |
Using dynamic parameters
After you create a dynamic parameter, use a placeholder in the following format to reference it in the query:
<%=parameter_placeholder%>
Important
If your dynamic parameter represents a date/time or string, wrap the placeholder in single quotes:
'<%=parameter_placeholder%>'
Failing to do this may produce runtime errors. For numeric values (e.g., INT, DECIMAL, FLOAT), single quotes are not required.
When using a dynamic parameter in a SQL query, its behavior depends on the type of extraction being run:
Full extraction: The Default value of the parameter is used.
Delta extraction: The most recent value of the parameter is used.
This enables you to run or schedule the same extraction for both delta and full extractions without additional configuration.
Note
This dynamic parameter behavior applies only to the Extraction Editor, because the extraction is performed using an SQL query as the sole input.Be mindful of the quotes around tables (or any objects in the query)
Some database systems support single or double quotes around tables and fields and some don’t. There is another category of systems that support backticks (Example - BigQuery). In the Extractions Editor, there could be errors thrown if you do not use the right quotation marks around the tables or fields.
Creating a dynamic parameter before writing the query
We recommend that you create a dynamic parameter before you write the query. This way you can schedule a full extraction and a delta extraction using one query. The full extraction (first time) will take the default value of the parameter. After the full extraction the new value of the parameter will be taken resulting in a filter that can subsequently extract delta records.